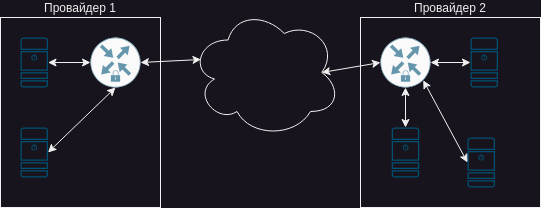
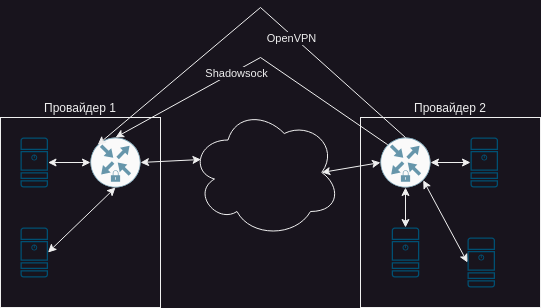
Наконец-то можно приступить к самому приятному: выбиванию окон во внешний мир. Или VPN. Ответы на вопросы зачем, почему и куда оставлю за рамками. Мне надо и все тут. Для организации канала буду использовать широко известный openvpn.
Ставим удобности.
yum -y install epel-release mc
Для начала подниму для проверки просто сервер. Без каких-либо излишеств.
yum -y install openvpn easy-rsa
cp /usr/share/doc/openvpn-*/sample/sample-config-files/server.conf /etc/openvpn
mcedit /etc/openvpn/server.conf
Конфиг после удаления лишнего получился примерно такой
port 1194
proto udp
dev tun
ca ca.crt
cert server.crt
key server.key
dh dh2048.pem
server 10.100.2.0 255.255.255.0
ifconfig-pool-persist ipp.txt
push "route 10.100.0.0 255.255.255.0"
;push "redirect-gateway def1 bypass-dhcp"
push "dhcp-option DNS 10.100.0.10"
push "dhcp-option DOMAIN local.multik.org"
duplicate-cn
keepalive 10 120
comp-lzo
user nobody
group nobody
persist-key
persist-tun
verb 3
Полностью по мануалу, без каких-либо отклонений. Значение каждой строчки можно посмотреть в документации.
Теперь ключи. Опять же, не отходя от канонов.
mkdir -p /etc/openvpn/easy-rsa/keys
cp -rf /usr/share/easy-rsa/2.0/* /etc/openvpn/easy-rsa
mcedit /etc/openvpn/easy-rsa/vars
Тут я поправил строки “по умолчанию”
export KEY_COUNTRY="RU"
export KEY_PROVINCE="RU"
export KEY_CITY="Moscow"
export KEY_ORG="VseMoe"
export KEY_EMAIL="multik@multik.org"
export KEY_OU="Internet"
...
export KEY_NAME="Server"
...
export KEY_CN="vpn.vsemoe.com"
Дальше просто лог команд, везде давим Enter.
cp /etc/openvpn/easy-rsa/openssl-1.0.0.cnf /etc/openvpn/easy-rsa/openssl.cnf
cd /etc/openvpn/easy-rsa
source ./vars
./clean-all
./build-ca
./build-key-server server
./build-dh
cd /etc/openvpn/easy-rsa/keys
cp dh2048.pem ca.crt server.crt server.key /etc/openvpn
cd /etc/openvpn/easy-rsa
./build-key client
Разрешаем форвард
mcedit /etc/sysctl.conf
net.ipv4.ip_forward = 1
sysctl -p
И стартуем сервер
systemctl enable openvpn@server.service
systemctl start openvpn@server.service
Теперь на хосте надо открыть порт 1194/udp и перебросить его на виртуалку с openvpn
-A INPUT -p udp -m state --state NEW -m udp --dport 1194 -j ACCEPT
-A PREROUTING -d 136.243.151.196/32 -i eth0 -p udp --dport 1194 -j DNAT --to-destination 10.100.0.133
И на самой виртуалке открыть тем или иным образом порт
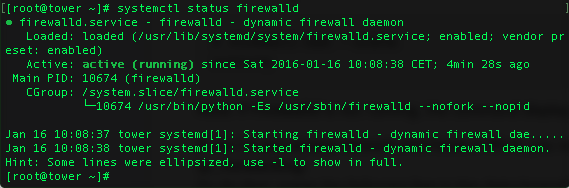
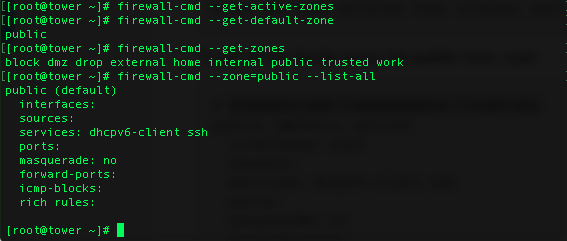
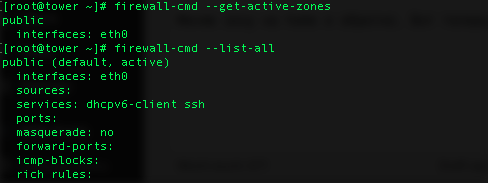
firewall-cmd --add-service=openvpn --permanent
firewall-cmd --permanent --add-port=53/udp
firewall-cmd --reload
Теперь перетаскиваем на клиента все client* файлы и ca.crt и делаем конфиг (обычный текстовый файл)
client
dev tun
proto udp
remote 136.243.151.196 1194
resolv-retry infinite
nobind
persist-key
persist-tun
comp-lzo
verb 3
ca ca.crt
cert client.crt
key client.key
Пробуем соедениться
$ sudo openvpn --config confif.vpn
Wed Jan 27 03:55:22 2016 OpenVPN 2.3.8 x86_64-redhat-linux-gnu [SSL (OpenSSL)] [LZO] [EPOLL] [PKCS11] [MH] [IPv6] built on Aug 4 2015
Wed Jan 27 03:55:22 2016 library versions: OpenSSL 1.0.1e-fips 11 Feb 2013, LZO 2.06
Wed Jan 27 03:55:22 2016 WARNING: No server certificate verification method has been enabled. See http://openvpn.net/howto.html#mitm for more info.
Wed Jan 27 03:55:22 2016 Socket Buffers: R=[212992->131072] S=[212992->131072]
Wed Jan 27 03:55:22 2016 UDPv4 link local: [undef]
Wed Jan 27 03:55:22 2016 UDPv4 link remote: [AF_INET]136.243.151.196:1194
Wed Jan 27 03:55:22 2016 TLS: Initial packet from [AF_INET]136.243.151.196:1194, sid=3dd59a35 34ce24da
Wed Jan 27 03:55:22 2016 VERIFY OK: depth=1, C=RU, ST=RU, L=Moscow, O=VseMoe, OU=Internet, CN=vpn.vsemoe.com, name=Server, emailAddress=multik@multik.org
Wed Jan 27 03:55:22 2016 VERIFY OK: depth=0, C=RU, ST=RU, L=Moscow, O=VseMoe, OU=Internet, CN=server, name=Server, emailAddress=multik@multik.org
Wed Jan 27 03:55:23 2016 Data Channel Encrypt: Cipher 'BF-CBC' initialized with 128 bit key
Wed Jan 27 03:55:23 2016 Data Channel Encrypt: Using 160 bit message hash 'SHA1' for HMAC authentication
Wed Jan 27 03:55:23 2016 Data Channel Decrypt: Cipher 'BF-CBC' initialized with 128 bit key
Wed Jan 27 03:55:23 2016 Data Channel Decrypt: Using 160 bit message hash 'SHA1' for HMAC authentication
Wed Jan 27 03:55:23 2016 Control Channel: TLSv1.2, cipher TLSv1/SSLv3 DHE-RSA-AES256-GCM-SHA384, 2048 bit RSA
Wed Jan 27 03:55:23 2016 [server] Peer Connection Initiated with [AF_INET]136.243.151.196:1194
Wed Jan 27 03:55:25 2016 SENT CONTROL [server]: 'PUSH_REQUEST' (status=1)
Wed Jan 27 03:55:25 2016 PUSH: Received control message: 'PUSH_REPLY,route 10.100.0.0 255.255.255.0,dhcp-option DNS 10.100.0.10,route 10.100.2.1,topology net30,ping 10,ping-restart 120,ifconfig 10.100.2.14 10.100.2.13'
Wed Jan 27 03:55:25 2016 OPTIONS IMPORT: timers and/or timeouts modified
Wed Jan 27 03:55:25 2016 OPTIONS IMPORT: --ifconfig/up options modified
Wed Jan 27 03:55:25 2016 OPTIONS IMPORT: route options modified
Wed Jan 27 03:55:25 2016 OPTIONS IMPORT: --ip-win32 and/or --dhcp-option options modified
Wed Jan 27 03:55:25 2016 ROUTE_GATEWAY 172.16.137.2/255.255.255.0 IFACE=eno16777736 HWADDR=00:0c:29:fa:0a:54
Wed Jan 27 03:55:25 2016 TUN/TAP device tun1 opened
Wed Jan 27 03:55:25 2016 TUN/TAP TX queue length set to 100
Wed Jan 27 03:55:25 2016 do_ifconfig, tt->ipv6=0, tt->did_ifconfig_ipv6_setup=0
Wed Jan 27 03:55:25 2016 /usr/sbin/ip link set dev tun1 up mtu 1500
Wed Jan 27 03:55:25 2016 /usr/sbin/ip addr add dev tun1 local 10.100.2.14 peer 10.100.2.13
Wed Jan 27 03:55:25 2016 /usr/sbin/ip route add 10.100.0.0/24 via 10.100.2.13
Wed Jan 27 03:55:25 2016 /usr/sbin/ip route add 10.100.2.1/32 via 10.100.2.13
Wed Jan 27 03:55:25 2016 Initialization Sequence Completed
Как видно по последней строчке, соединение установилось. Пробуем добраться до любого хоста “внутри” сети.
$ ssh root@10.100.0.10
ssh: connect to host 10.100.0.10 port 22: No route to host
Облом. По простой причине – ничего в сети 10.100.0 не знает про сеть 10.100.2, которую я отдал под VPN. Самое простое решение – включить маскарадинг на выходе
firewall-cmd --permanent --add-masquerade
firewall-cmd --reload
Пробую еще раз
$ ssh root@10.100.0.10
The authenticity of host '10.100.0.10 (10.100.0.10)' can't be established.
ECDSA key fingerprint is fb:c1:72:a2:9a:a1:df:f5:d0:95:09:a4:3b:2e:9d:68.
Сработало. Это хорошо. Теперь немного добавим безопасности путем добавление пре-авторизационного ключа. Опять же, по мануалу
openvpn --genkey --secret ta.key
tls-auth ta.key 0
В принципе, тут можно остановиться. Сервер работает, создаешь по ключу на клиента и вперед. Но мне так не охота. Я хочу сделать так, что бы конфигурационный файл был у всех одинаковый, а пользователи авторизовались по классическому логину и паролю. А логины и пароли брались бы из FreeIPA.
Опять же, вариантов много. Самый распространенный – это использование freeipa как ldap сервера. Мне лично лень. Я решил воспользоваться вариантом, когда freeipa авторизует пользователей в системе (так как это стандартный способ), а openvpn авторизовать уже через пользователей в системе.
Ставим на vpn все необходимое и подключаемся к ипе (подробности в ранних постах).
yum install -y ipa-client
ipa-client-install --mkhomedir
И тут оно обламывается. По простой причине – для vpn.local.multik.org нет адреса в базе. А у машины два локальных интерфейса и какой использовать для чего – непонятно.
Идем в виртуалку с ipa и добавляем
[root@ipa ~]# kinit admin
Password for admin@LOCAL.MULTIK.ORG:
[root@ipa ~]# ipa dnsrecord-add
Record name: vpn
Zone name: local.multik.org
Please choose a type of DNS resource record to be added
The most common types for this type of zone are: A, AAAA
DNS resource record type: A
A IP Address: 10.100.0.133
Record name: vpn
A record: 10.100.0.133
И снова пробуем – теперь все получится.
Теперь небольшой трюк. Что бы не давать по умолчанию доступ до VPN всем, я создам новый “сервис”.
cd /etc/pam.d/
ln -s system-auth openvpn
Теперь Осталось мелочь – создать в ипе HBAC сервис openvpn и установить правила. Создаем сервис, группу для него и соединяем вместе
[root@ipa ~]# ipa hbacsvc-add openvpn
----------------------------
Added HBAC service "openvpn"
----------------------------
Service name: openvpn
[root@ipa ~]# ipa hbacrule-add allow_openvpn
-------------------------------
Added HBAC rule "allow_openvpn"
-------------------------------
Rule name: allow_openvpn
Enabled: TRUE
[root@ipa ~]# ipa hbacrule-add-service allow_openvpn --hbacsvcs=openvpn
Rule name: allow_openvpn
Enabled: TRUE
Services: openvpn
-------------------------
Number of members added 1
-------------------------
Проверяю, что натворил.
[root@ipa ~]# ipa hbacrule-find allow_openvpn
-------------------
1 HBAC rule matched
-------------------
Rule name: allow_openvpn
Enabled: TRUE
Services: openvpn
----------------------------
Number of entries returned 1
----------------------------
Добавляю к правилу пользователя и хост
[root@ipa ~]# ipa hbacrule-add-user allow_openvpn --user=multik
Rule name: allow_openvpn
Enabled: TRUE
Users: multik
Services: openvpn
-------------------------
Number of members added 1
-------------------------
[root@ipa ~]# ipa hbacrule-add-host allow_openvpn --hosts=vpn.local.multik.org
Rule name: allow_openvpn
Enabled: TRUE
Users: multik
Hosts: vpn.local.multik.org
Services: openvpn
-------------------------
Number of members added 1
-------------------------
Проверяю, что сработает на меня и на админа (который вроде как и не должен иметь доступ)
[root@ipa ~]# ipa hbactest --user=admin --host=vpn.local.multik.org --service=openvpn
--------------------
Access granted: True
--------------------
Matched rules: allow_all
Not matched rules: allow_openvpn
[root@ipa ~]# ipa hbactest --user=multik --host=vpn.local.multik.org --service=openvpn
--------------------
Access granted: True
--------------------
Matched rules: allow_all
Matched rules: allow_openvpn
Как вижу, в системе есть правило по умолчанию, которое дает доступ всем до всего. Но если его просто выкусить, то я тупо лишусь доступа И по ssh тоже. Поэтому надо сделать аналогичное для ssh
[root@ipa pam.d]# cd
[root@ipa ~]# ipa hbacsvc-add sshd
ipa: ERROR: HBAC service with name "sshd" already exists
Опс, сервис такой уже по умолчанию есть. Ну пойду дальше
[root@ipa ~]# ipa hbacrule-add allow_sshd
----------------------------
Added HBAC rule "allow_sshd"
----------------------------
Rule name: allow_sshd
Enabled: TRUE
[root@ipa ~]# ipa hbacrule-add-service allow_sshd --hbacsvcs=sshd
Rule name: allow_sshd
Enabled: TRUE
Services: sshd
-------------------------
Number of members added 1
-------------------------
[root@ipa ~]#
ipa hbacrule-add-user allow_sshd --user=multik
ipa hbacrule-add-host allow_sshd --hosts=vpn.local.multik.org
Проверяю
[root@ipa ~]# ipa hbactest --user=admin --host=vpn.local.multik.org --service=sshd
--------------------
Access granted: True
--------------------
Matched rules: allow_all
Not matched rules: allow_openvpn
Not matched rules: allow_sshd
[root@ipa ~]# ipa hbactest --user=multik --host=vpn.local.multik.org --service=sshd
--------------------
Access granted: True
--------------------
Matched rules: allow_all
Matched rules: allow_sshd
Not matched rules: allow_openvpn
Все на месте. Выкусываю нафиг
[root@ipa ~]# ipa hbacrule-disable allow_all
------------------------------
Disabled HBAC rule "allow_all"
------------------------------
Согласно выводу выше, я теперь не могу залогиниться на хост vsemoe-com пользователем multik.
[root@ipa ~]# ssh multik@vsemoe-com
multik@vsemoe-com's password:
Connection closed by UNKNOWN
Не соврала система. “Не пущаит”. Проверяю почему
[root@ipa ~]# ipa hbactest --user=multik --host=vsemoe-com.local.multik.org --service=sshd
---------------------
Access granted: False
---------------------
Not matched rules: allow_openvpn
Not matched rules: allow_sshd
Добавляю хост, как разрешенный к коннекту на него по ssh
[root@ipa ~]# ipa hbacrule-add-host allow_sshd --hosts=vsemoe-com.local.multik.org
Rule name: allow_sshd
Enabled: TRUE
Users: multik
Hosts: vpn.local.multik.org, vsemoe-com.local.multik.org
Services: sshd
-------------------------
Number of members added 1
-------------------------
Будет пускать?
[root@ipa ~]# ipa hbactest --user=multik --host=vsemoe-com.local.multik.org --service=sshd
--------------------
Access granted: True
--------------------
Matched rules: allow_sshd
Not matched rules: allow_openvpn
Должно. Проверяю
[root@ipa ~]# ssh multik@vsemoe-com
multik@vsemoe-com's password:
Last failed login: Thu Jan 28 12:53:43 MSK 2016 from 2a01:4f8:171:1a43:5054:ff:fea4:8c6 on ssh:notty
There was 1 failed login attempt since the last successful login.
Last login: Mon Jan 25 16:51:46 2016 from 10.100.0.254
Как говорится, работает. Теперь последняя проверка: пустит ли пользователя multik на хосте vpn для сервиса openvpn?
[root@ipa ~]# ipa hbactest --user=multik --host=vpn.local.multik.org --service=openvpn
--------------------
Access granted: True
--------------------
Matched rules: allow_openvpn
Not matched rules: allow_sshd
Для vpn пустит, а по ssh не пустит. Теперь остались сущие мелочи. Добавялем в конфиг сервера
plugin /usr/lib64/openvpn/plugins/openvpn-plugin-auth-pam.so openvpn
а в конфиг клиента
auth-user-pass
и пробуем
$ sudo openvpn --config confif.vpn
Thu Jan 28 04:57:42 2016 OpenVPN 2.3.8 x86_64-redhat-linux-gnu [SSL (OpenSSL)] [LZO] [EPOLL] [PKCS11] [MH] [IPv6] built on Aug 4 2015
Thu Jan 28 04:57:42 2016 library versions: OpenSSL 1.0.1e-fips 11 Feb 2013, LZO 2.06
Enter Auth Username: ******
Enter Auth Password: ***********
Как видим, спросило логин и пароль. И дальше как обычно. Но каждый раз вводить логин и пароль лень. Всякие ViscoCity и прочие умеют это. Научим и консольного клиента.
Сделаем обычный текстовый файлик из 2х строчек: логина и пароля. И укажем его имя сразу после auth-user-pass. Если все сделано правильно, то openvpn ничего не будет спрашивать, а просто возьмет и прицепится.
Теоретически, на этом можно и закончить процесс. Но некрасиво как-то. “Клиентами” моего сервиса будут люди, далекие от техники. Дизайнеры всякие и менеджеры. Пока им объяснишь, чего куда совать и на что нажимать …
Технология очень простая. Берем исходный конфиг для клиента, и добавляем к нему следующие строки
key-direction 1
<ca>
—–BEGIN CERTIFICATE—–
ca.crt
—–END CERTIFICATE—–
</ca>
<cert>
—–BEGIN CERTIFICATE—–
client.crt
—–END CERTIFICATE—–
</cert>
<key>
—–BEGIN PRIVATE KEY—–
client.key
—–END PRIVATE KEY—–
</key>
<tls-auth>
—–BEGIN OpenVPN Static key V1—–
ta.key
—–END OpenVPN Static key V1—–
</tls-auth>
Внутрь просто копируем содержимое соответствующих файлов. Любым текстовым редактором. Ну и убираем строки
ca ca.crt
cert client.crt
key client.key
Полученному файлу надо поставить расширение ovpn и его магическим образом станут понимать практически все системы, заявляющие о поддержке openvpn.
Всё. Я получил в свое распоряжение VPN сервер. Управляемый хоть из консоли, хоть из веб-морды (как? я не писал? сходите браузером на адрес ipa сервера). Ну вообще-то не только VPN сервер, но в этой рассказке я писал только про VPN.
Удачи!