Одним из самых распространенных вариантов обмена информации с внешним устройством это последовательный порт. Давно известная технология, куча примеров для любых языков программирования и все ошибки давно уже найдены и описаны. Сейчас обычно используется COM-over-USB, так как переписывать ничего не надо.
Но разрабатывая очередное устройство у меня возникли смутные ощущения, что есть некие тормоза про общении с устройством. Решил проверить.
Для начала сгенерировал в STM32CubeMX пустой проект. В котором есть только USB и он определен как CDC.
Потом прямо в коде приема блока тут же его отправляю его назад. Кусок из usbd_cdc_if.c
static int8_t CDC_Receive_FS(uint8_t* Buf, uint32_t *Len)
{
/* USER CODE BEGIN 6 */
USBD_CDC_SetRxBuffer(&hUsbDeviceFS, &Buf[0]);
CDC_Transmit_FS(&Buf[0], *Len);
USBD_CDC_ReceivePacket(&hUsbDeviceFS);
return (USBD_OK);
/* USER CODE END 6 */
}И написал маленькую программку на питоне, которая тупо спамит в порт увеличивающимися блоками и замеряет скорость. Можно взять тут https://github.com/kiltum/usb-rs485/blob/master/test/test/test.py
import time
import threading
import serial
# f042
#ser = serial.Serial(port='/dev/cu.usbmodem2058335047481')
# f303
ser = serial.Serial(port='/dev/cu.usbmodem2057385756311')
ser.isOpen()
# For windows
#ser.set_buffer_size(rx_size=262144, tx_size=262144)
bytesReceived = 0
minimalSpeed = 10000000
maximumSpeed = 0
counterStep = 0
blockSize = 1
shallExit = 0
def res():
global bytesReceived
global minimalSpeed
global maximumSpeed
global counterStep
global blockSize
global ser
global shallExit
if minimalSpeed > bytesReceived:
if bytesReceived > 0:
minimalSpeed = bytesReceived
if maximumSpeed < bytesReceived:
maximumSpeed = bytesReceived
bytesReceived = 0
counterStep = counterStep + 1
if counterStep > 60:
print("BlockSize:", blockSize, "Minimal:", minimalSpeed, "Maximum:", maximumSpeed,
"Average:", round((minimalSpeed+maximumSpeed)/2048), "kb/s")
with open("result.csv", "a") as myfile:
myfile.write(str(blockSize) + "," + str(minimalSpeed) + "," + str(maximumSpeed) + "\n")
ser.read(ser.inWaiting())
counterStep = 0
minimalSpeed = 100000000
maximumSpeed = 0
blockSize = blockSize * 2
if shallExit == 0:
threading.Timer(1, res).start()
with open("result.csv", "w") as myfile:
myfile.close()
res()
while 1:
if blockSize > 65536:
shallExit = 1
exit(0)
s = "A" * blockSize
b = s.encode()
ser.write(b)
bytesReceived = bytesReceived + ser.inWaiting()
ser.read(ser.inWaiting())
Сильно я не заморачивался, поэтому указать нужный порт придется вам самим прямо в коде. “Человекочитаемые” программа пишет в консоль и попутно генерирует result.csv для импорта в excel или другую подобную программу
Под рукой у меня оказалось только два stm32 с usb: F042 и F303. Оранжевая линия это максимальная скорость, синяя – минимальная. Такие прыжки максимальной скорости вызваны буферизацией у всех участников процесса. Ну по крайней мере я сейчас так думаю.
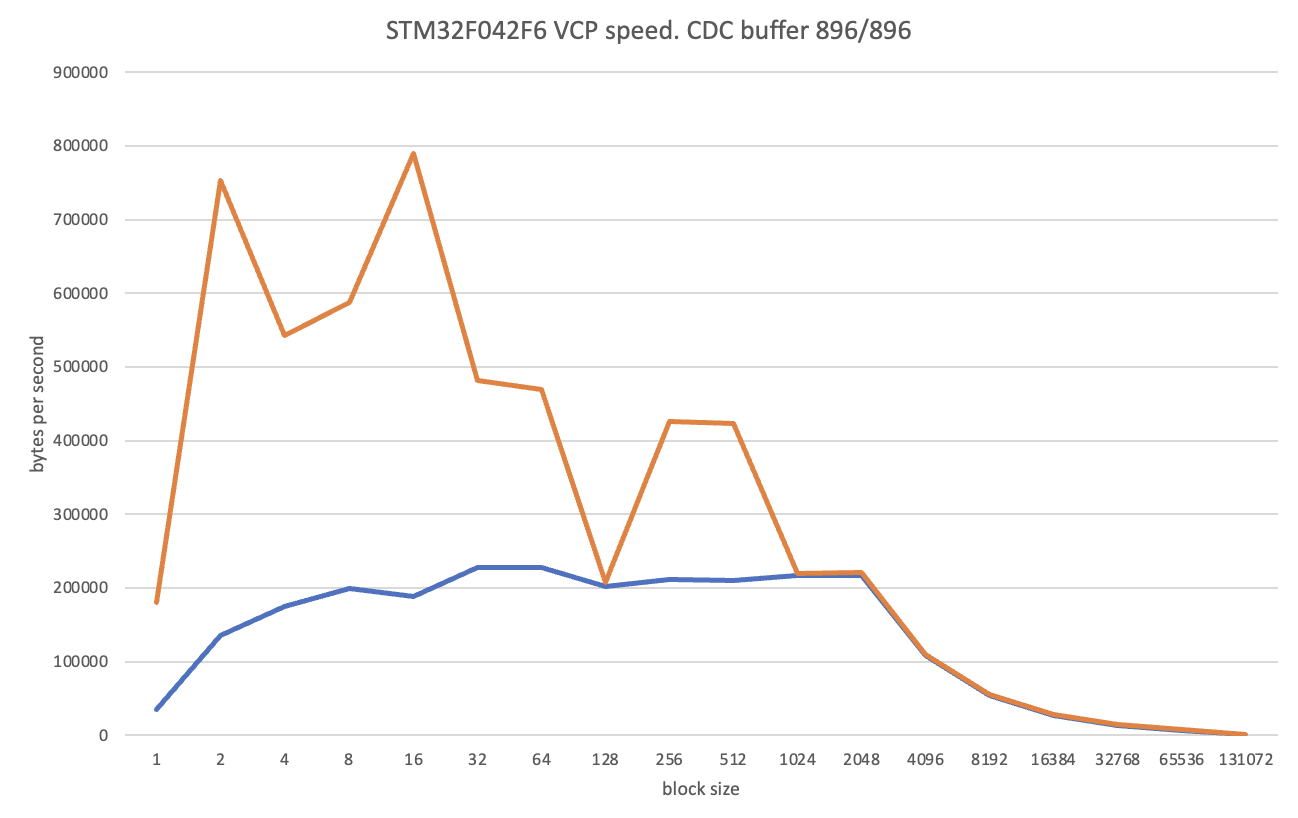
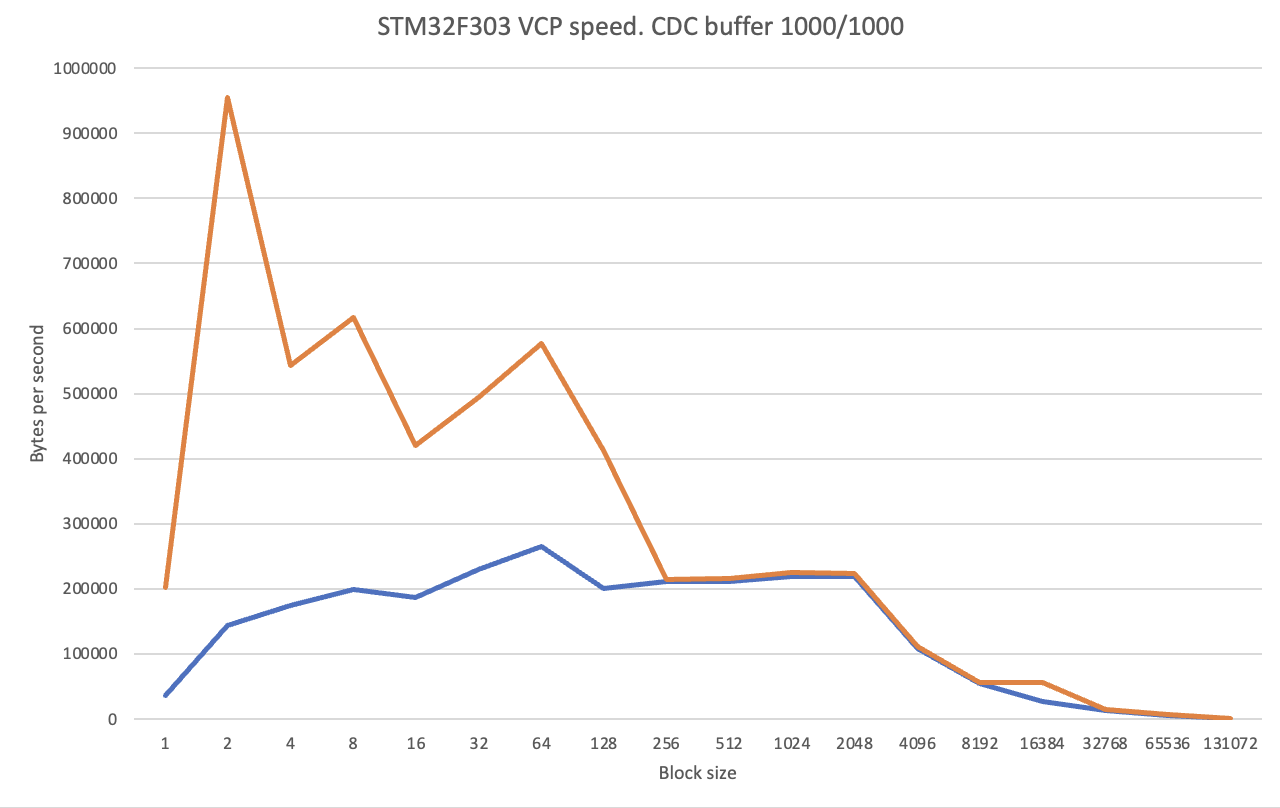
Результаты довольно показательные. Как найду еще процессоров – попробую повторить. Но пока можно сказать, что не стоит использовать блоки больше 128-256 байт и можно надеяться на скорость не менее 200 килобайт в секунду.
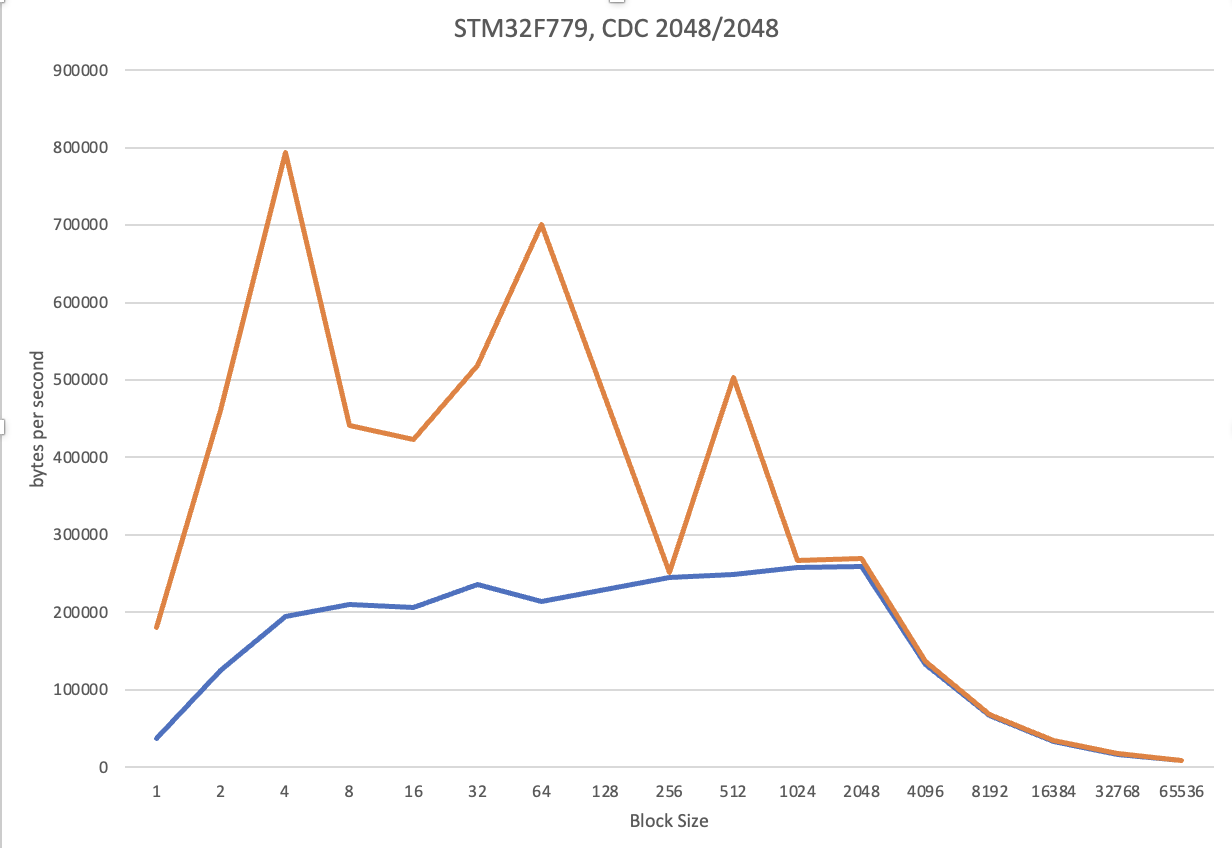
UPDATE1: Добавил график от F779. Суть та же. Видимо, где-то прямо в коде CDC у stm большие проблемы