Жил я долго и счастливо с ssh, где приватный ключ хранился в Yubikey и GnuPG (https://blog.kiltum.tech/2025/03/04/yubikey-ssh-final/). Все было хорошо до тех пор, пока мне не потребовалось засунуть приватный ключ в другую систему, которая тупа и вообще ничего другого не принимает как класс.
“Ну фигня вопрос, счас загуглю и быстренько сделаю”. А вот фиг по всей моей физиономии. Все рецепты, что предлагал гугл вместе с нейронками – абсолютно не рабочие. По одной простой причине: они все расчитаны на то, что ключи будут в формате RSA. А у меня-то ed25519. В итоге то у gpg нет такого ключика, то формат не туда, то еще какая фигня на постном масле.
Очень похоже на правду, поэтому командуем разшифровать этот файл
$ echo 'PASSWD AE9CE2AC2E83722BE5F0508C7D131E91CD5FA317' | gpg-connect-agent
S KEYGRIP AE9CE2AC2E83722BE5F0508C7D131E91CD5FA317
S CACHE_NONCE DF9204BEA240BA3CD2986C2E
OK
Оно спросит пароль, потом новый (оставьте пустым) и еще раз “уверены ли мы”. И вот теперь мы его обнаруживаем расшифрованным (я данные заменил на Х)
#!/usr/bin/env python
# /// script
# requires-python = ">=3.13"
# dependencies = [
# "cryptography",
# ]
# ///
import os
import pathlib
import sys
import cryptography.hazmat.primitives.serialization
import cryptography.hazmat.primitives.asymmetric
keygrip = sys.argv[1]
gpg_file = pathlib.Path("~/2/.gnupg/private-keys-v1.d/").expanduser() / f"{keygrip}.key"
with open(gpg_file, "r") as f:
gpg_data = f.read()
# Rather than elegantly parse the S-expression in the .key file, split it on
# the hashes which surround the key material, and pull out the public (q) and
# private (d) parts.
(_, gpg_q, _, gpg_d, _) = gpg_data.split("#")
gpg_d = bytes.fromhex(gpg_d)
d = cryptography.hazmat.primitives.asymmetric.ed25519.Ed25519PrivateKey.from_private_bytes(
gpg_d
)
private_bytes = d.private_bytes(
encoding=cryptography.hazmat.primitives.serialization.Encoding.PEM,
format=cryptography.hazmat.primitives.serialization.PrivateFormat.OpenSSH,
encryption_algorithm=cryptography.hazmat.primitives.serialization.NoEncryption(),
)
os.umask(0o0077)
ssh_key_file = pathlib.Path("~/.ssh").expanduser() / f"id_ed25519.{keygrip}"
with open(ssh_key_file, "w") as f:
f.write(private_bytes.decode())
print(f"SSH key written to {ssh_key_file}")
И пущаем его (как ставить модули в питон, если у вас их нет – в гугл)
python3 t.py AE9CE2AC2E83722BE5F0508C7D131E91CD5FA317
SSH key written to /Users/vvkaloshin/.ssh/id_ed25519.AE9CE2AC2E83722BE5F0508C7D131E91CD5FA317
Успешный успех! Я проверил: ключик действительно тот и ssh -i проглатывает его совершенно без каких-либо стеснений. Теперь осталось засунуть его куда надо и подчистить за собой ошметки и незашифрованные ключи.
В общем-то, провайдерский роутер RX-33412 вполне себе железка. Подключили и он работал совершенно без каких-либо претензий. Правда, я сразу на нем отключил WiFi, ибо по отзывам, оно обожает перегреваться и тащит за собой все остальное. А оно мне надо? Тем более у меня есть нормальная WiFi сеть с мешами и прочим, чего этот роутер не умеет.
В чем была боль? В двойном NAT. Чтобы пробросить порты, надо было сначала вручную на первом роутере прописать, потом на втором. Ну и лишние миллисекунды потерь на роутинге тоже резали ножом мою нежную ИТ душу. Итого было принято решение перестать выкапывать стюардессу и сделать по-нормальному.
А как по-нормальному? Вместо роутера нужен был бридж. Иначе говоря, провайдерский роутер должен был превратиться в тупой транслятор “оптика – ethernet”. И, в принципе, он это умеет: достаточно просто в настройках повернуть крыжик. Но (опять это но!) в куче сообщений на форуме 4pda были жалобы, что если что, то тупая автоматика ростелекома через TR-069 сбрасывает эти настройки на “умолчательные”, сиречь роутер вместо бриджа. Решения, конечно, есть. Первое это обратиться в саппорт и попросить их у себя в настройках сменить. Второе: купить ONT коробочку и сделать все самим. А провайдерский оставить в качестве резерва. Я пошел по второму варианту.
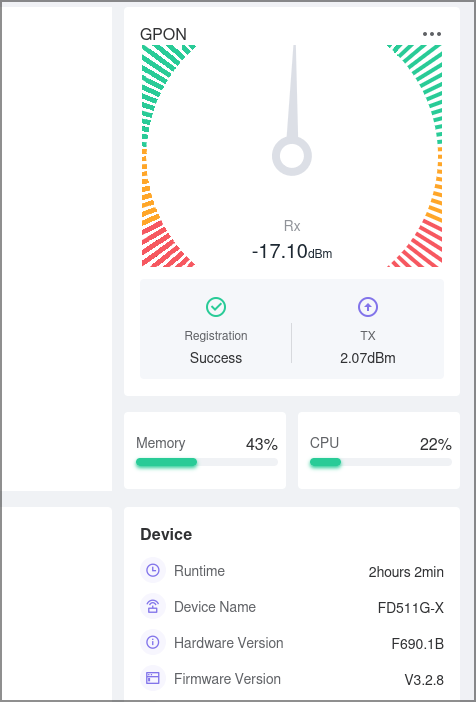
Купил Оптический абонентский терминал xPON ONT/ONU 1GE FD511G-XA MINI 1 порт GPON/EPON, 1490/1310 нм, 20 км, SC/APC. Пока он ехал, скопировал все относящееся к GPON, что нашел. Почитал 4pda, нашел метод взлома, выдающий пароль от superadmin. Получил, походил посмотрел. В общем-то ничего полезного (кроме настроек TR-069) не нашел. Но все равно записал в блокнотик.
Приехала онушка. Воткнул кабель, прописал 192.168.101.10/24, зашел с кредами adminisp/adminisp и принялся смотреть. Но опять смотреть оказалось нечего. В WAN создаем бридж с VLAN 10, в GPON прописываем GPON_SN, спертый с провайдерского роутера, остальные поля удаляем. И сохраняем, вернее пытаемся сохранить. Оказывается, 3я версия прошивки не дает полю SN Password быть пустым. Еще немного погуглил и забил туда десять ноликов. Сохранил.
Подключил оптику, включил питание и …
Дальше уже совсем просто: в моем роутере прописал PPPoE, вбил логин и пароль и оно заработало.
Последний шаг нужен для тех, у кого UniFi Cloud Gateway Ultra. UCG не умеет делать бридж и роутинг на одном порту. В итоге после подключения я потерял доступ к админке ONT. Мелочь? Мелочь, но не приятная. Как теперь смотреть красивые циферки-то? Благодаря тому, что внутри у UCG обычный линукс, идем в консоль и запускаем пару комманд
ip addr add dev eth4 local 192.168.101.2/24
iptables -t nat -A POSTROUTING -o eth4 -d 192.168.101.0/24 -j SNAT --to 192.168.101.2
Теперь все снова доступно. Как говорится, попробуйте повторить это на кинетике … Минус только один: после перезагрузки это надо будет повторить 🙂
Я давний фанат keenetic’ов. Ну как минимум был до последних событий. Вся их линейка абсолютно соответствовала моему главному принципу “не трахай мне мозг”. Купил, достал, подключил, соеденил, забил логины-пароли и оно работает себе. Так продолжалось… ну лет много в общем.
Но все изменилось с последней реорганизации сети у меня дома. Я наконец-то дорос до отдельной комнаты, где поселились сервера в стойке, нормальные коммутаторы и прочие патч-панели. Поглядев на получившееся великолепие, я начал пересаживать кинетик на новое место жительства.
И тут начались странности и жалобы. Если проводная часть (читай стационарные компы и виртуалки) работали отлично, то WiFi колбасило, причем очень странно. Например, у меня появился “заколдованный” угол, где включаешь любой кинетик и через некоторое время у него пропадает диапазон 5ГГц. И время колеблется от “сразу” до “ну где-то через полчаса”. Ок, пока разбираемся с 5ГГц, можно ведь пожить и на 2х, верно ведь? Нет, не верно. Не знаю, что там и где не стыкуется у кинетика с маком, но его иногда начало перепинывать от точки к точке. И ладно бы просто перепинывало, но иногда его забрасывало на самую удаленную точку, где сигнал иногда терялся. А потеря сигнала – потеря коннекта – сброс всех впн и прочих соединений. Быстрая припарка в виде близкой точки доступа, включенной в меш, помогла, но это же костыль…
В общем, я дошел до ручки и пошел писать в техподдержку кинетика. Впервые за много лет я не смог побороть сетевую часть. Надо отдать должное, там довольно быстро вьехали в суть и практически на первом ответе выдали ответ. Вот он дословно.
Для корректной работы Wi-Fi системы, от стороннего оборудования в сети требуется пропуск STP и LLDP.
В Wi-Fi системе протокол STP используется для управления связями между ретрансляторами. LLDP – для определения контролера в сети. Если промежуточное оборудование в сети вмешивается в работу STP/LLDP, либо не пропускает пакеты BPDU протокола STP – работа Wi-Fi системы будет нарушена. Симптомы при этом: петли, сетевой шторм, в случае если ретрансляторы видят транспортную сеть контроллера и подключаются к ней. А если ретрансляторы транспортную сеть не видят, то на них остается включенным беспроводной клиент, который вхолостую сканирует эфир, вызывая потери на собственной точке доступа. Могут возникать разные негативные эффекты.
Если все ретрансляторы подключены кабелями, можно отключить на Keenetic-контроллере “Беспроводную транспортную сеть” в настройках Wi-Fi системы, это, как минимум, уберет возможную петлю. Но, если проблема в STP, это не решает ее полностью, лишь отчасти маскирует ее.
Если имеется оборудование с поддержкой STP, его нужно настраивать: можно попробовать отключить на нем STP/RSTP/MSTP, но тогда есть вероятность, что будут отбрасываться BPDU-пакеты, что тоже не годится. Может помочь включение опции BPDU Flooding, если такая есть.
Нужно настроить таким образом, чтобы у всех коммутаторов был меньше приоритет в топологии STP и они не занимали место Keenetic-контроллера. Корнем дерева STP должен быть контроллер. По умолчанию и Keenetic, и коммутаторы имеют значение STP Bridge Priority 32768 DEC или 8000 HEX. Чем ниже значение, тем выше приоритет узла. Нужно либо повысить значение на коммутаторах, либо понизить на Keenetic.
Мне потом его еще раз прислали слово-в-слово, из чего я сделал вывод, что эта проблема шаблонная, как и рецепты по ее исправлению. Ну если с STP есть вариант попробовать, то с LLDP полный швах. Ни один свитч попросту не пропустит LLDP пакеты через себя, потому что это нарушает стандарты.
Если пропустить дальнейшую переписку и перейти сразу к сути, то выявляются два пункта, которые стали причиной моего отказа от кинетиков.
Пункт 1: Между кинетиками должны быть только хабы. Сейчас они маскируются под “неуправляемые свичи”. Или сами кинетики. Как выяснилось, их сетевая часть плюет на стандарты в этом месте.
Пункт 2: Пока точка доступа не видит контроллер по LLDP, она НЕ ПЕРЕСТАЕТ сканировать сеть в поисках транспортной. Пофиг на то, что контроллер видит точку доступа и рулит ей. Пофиг на пинги и прочее. Нет lldp? Нет и 5ГГц. Это и стало причиной глюков по 5ГГц. Точка доступа поднимает SSID, набирает клиентов, гонит трафик… Потом просыпается что-то внутри “ой, а где контроллер” и она начинает сканировать эфир, посылая клиентов нахер. Не найдя, она поднимает все назад и процедура повторяется. А клиенты шарахаются с точки на точку и с канала на канал.
Быстро собрав отдельную сеть для кинетиков и пригасив негатив (читай: у мака wifi стал отваливаться не каждые 10-15 минут, а пару раз за день), я принялся искать варианты. Первыми попались на глаза и ушли консьюмерские дивайсы. Asus, TP-Link и прочие Xiaomi. Почитав обзоры и погуглив разное, я решил, что повторения болей мне не надо. Где-то нет меша через провод, где-то управлялка только через мобильник, где-то еще какая закавыка…
Ладно, пойдем к корпоратам. Так сказать, чем мой дом не SOHO? Первым попал под микроскоп microtik. Первым минусом стало то, что WiFi у микротиков традиционно слабый. Но это мелочи, можно просто побольше точек напихать, благо у меня чердак неэксплуатируемый. Но вот winbox и прочее стали барьером. Я как-то привык к принципу “рулим отовсюду и без особых заморочек”.
И тут на сцену вышел Ubiquiti. У них есть решения под любые (хорошо, кратно превышающие мои потребности) задачи. Ну и плюс множество восторженных отзывов, что это работает. Не проблема, беру заказываю одну точку доступа на пробу.
Пока она едет, ставлю в виртуалку UniFi Network, единственная задача которой рулить всей сетевой частью дивайсов компании. Есть еще всякие UniFi Access и NVR, но мне не нужны ни замки на двери (читай СКУД), ни запись с камер.
Наконец приехала точка доступа. Первые впечатления: полный восторг! Шаблон для дырочек в комплекте, причем сразу с уровнем. Крепления на стену и на фальшпотолок. А если нужно что-то более экзотическое, то велкам в магазин: там есть хоть на трубы, хоть на черта лысого. Пошел в закрома, нашел уголок и тупо прикрепил к стропилам крыши.
Воткнул в РОЕ коммутатор, раздал VLAN… Пошел в UniFi Network, захватил точку и… Всё. Реально все. Она заработала, показала всё, что надо и вообще как будто тут и была. “Подозрительно”, решил я и принялся ее гонять. Диапазоны, каналы, устойчивость к температурам (на улице была жара +40 в тени, под крышей было до +65) и прочее. Да, куча функционала в network не работало, ибо нужны были другие железки от unifi, но именно к точке доступа претензий не возникло ни одной. Даже мак любезно перешел на нее и был совершенно удовлетворен сетевой частью.
Прошла неделя. Без замечаний. Я заказал UniFi Cloud Gateway (читай: роутер), сверху USW Lite 8 POE (читай коммутатор с РОЕ) и еще три точки доступа. Пока железо ехало, читал гайды и смотрел видосики. На youtube реально куча видео, рассказывающих про все аспекты: начиная от “инсталяция с нуля для нубов” и заканчивая “у меня есть ранчо, чего-то вайфай на горе за 200м от дома плохо ловится”.
Приехало железо. Быстренько раскидал как попало, воткнул куда придется и принялся играться. И оно опять-таки подозрительно все заработало буквально с первой попытки. Да, проблемы возникли.
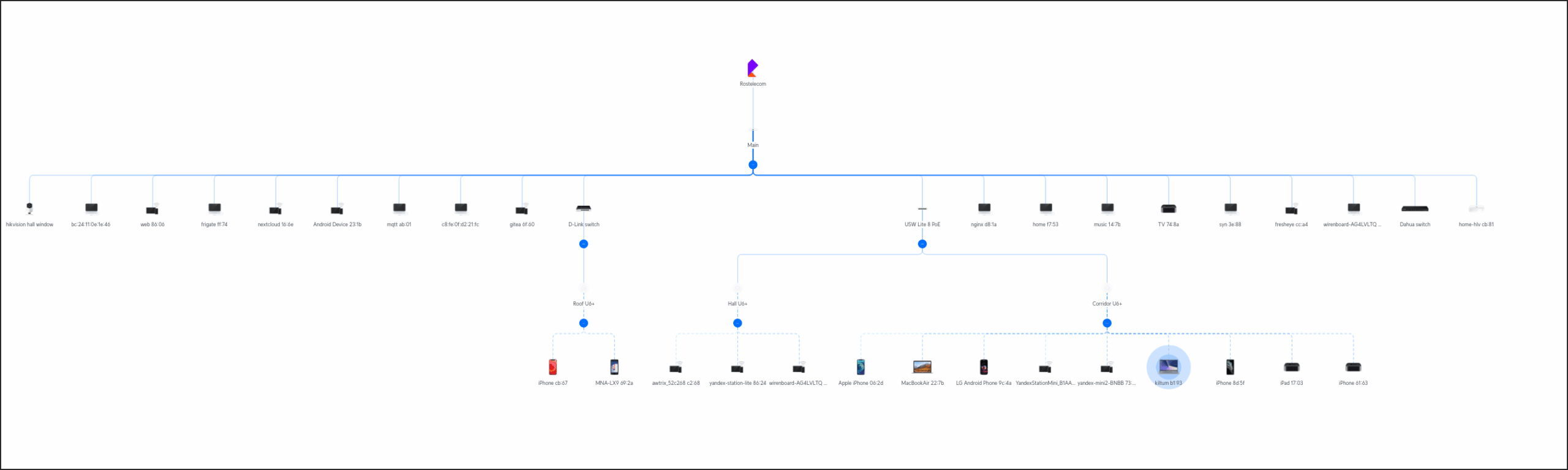
Ну как проблемы. Так, фичи. Например, встроенный показометр топологии почему-то очень вольно обращается с “чужими” свичами. Если поглядеть на картинку сверху, то выглядит, как куча всего подключено напрямую в Main. В реальности они все подключены через свои свитчи. Но это мелочи. В реальности все работает без каких-либо “пропусков LLDP и понижения приоритета STP”.
Наигравшись, через неделю я рано утром выключил все кинетики и переименовал WiFi сеть. И затаился в ожидании “ну чего оно опять не работает”. А фигу. Мне уже стыдно немного за повторения, но оно заработало так, как и ожидалось. Моя лакмусовая бумажка качества сети в виде мака вообще не подавала никаких признаков кислотности в округе. Я даже взял смелость походить между точек доступа во время видеоконференции. Раньше это приводило к секундным паузам, сейчас нет.
Прошла еще одна неделя. Проблем нет. Все работает, все показывается. Все мои 38 устройств не высказывают никаких проблем.
Следующим шагом станет постепенное избавление от “соплей”, которые я навешал в серверной при игрищах и переезде. В сторону: патч-панель это хорошо!
Но это дела дней грядущих. Теперь краткое резюме о том, в чем же keenetic проигрывает unifi. В том порядке, что пришло в голову.
Все (вообще все) дивайсы от убика умеют в vlan и являются управляемыми. Причем управляемыми из одной точки. При числе дивайсов более одного это дает резкий буст в контроле над сетью. У кинетика надо бегать по каждому отдельно, причем часто без права на ошибку. Иначе сброс и начинай все заново.
Все (опять вообще все) конечные дивайсы от убика умеют в РОЕ. Или раздавать или питаться от него. У кинетика это умеет только voyager (и вроде кто-то еще). Отсутствие необходимости в розетке рядом (или приобретать отдельный РОЕ сплиттер) очень и очень выручает.
Управление сетями WiFi вообще не конек кинетика. У убика можно задать, какая сеть на какой точке будет светиться, а какая нет. У кинетика только все разом и только все вместе.
Управляемость сетью у кинетика тоже на уровне плинтуса. Чтобы развести разные сети по разным VLAN, дать доступ одним и запретить другим, отправить трафик не на маршрут по умолчанию, а куда-то еще – надо трахаться. Реально проще всех оставить в одной сети и не мучаться. У убика это делается парой кликов в админке.
Динамические протоколы маршрутизации. У убика все есть. И OSPF и BGP. У кинетика только RIP и тот в зачаточном состоянии. А это значит, что сделать обход мракобесия РКН на убике на порядок проще и надежнее. И я сделал и оно реально проще.
Убик внутри это обычный линукс. Можно зайти по ssh и посмотреть, как оно все там внутри жужжит. Policy Engine? Это iptables с кучей правил. BGP? Это обычный FRR. Команда ip полностью функциональна и с ней можно сотворить внутри системы что угодно. Даже на точке доступа все это есть и работает. У кинетика же внутри какой-то кастрированный шелл, к которому нет документации. Ну нельзя же считать докой гуляющий по сети pdf от старой гиги.
Кинетик угрюмо курит в углу после вопросов по техническим возможностям. Wifi7? Они только-только WiFi6 освоили. 10Гб порты? Вы чего? У нас 2,5Гб только начали появляться. SFP? Вот вам гигабит, его всем хватает! Уличные точки доступа? Ну под крышей поставьте, норм же!
И наконец то, что импортные называют observability. Посмотреть, где и что происходит в сети, кинетик попросту не умеет.
Может показаться, что я хаю кинетик, но это не так. Вообще так (смаил), но возможно я просто перерос его возможности и наши курсы разошлись…
Стоял у меня Plex на synology, раздавал видосики и никак к себе внимание не привлекал. Однако после очередной переделки сети я обнаружил, что все клиенты стали ругаться на недоступность сервера. Зашел в админку, там пишут, что проблемы с сервером.
Ок, потыкал сюда, потыкал туда… Нет, не работает у тебя plex и все тут. Ок, пошел скачал с сайта последнюю версию, обновил. Ничего. Удалил вообще все, поставил и вуаля: You do not have permission to access this server. Пошел гуглить. Везде идиотские советы типа поставь DNS в 1.1.1.1 и 8.8.8.8 и все заработает.
Наконец в какой-то инструкции прочитал, что надо нажать кнопочку claim в админке. Но меня в админку не пускает! Читаю дальше. Везде в инструкции советы типа “найдите в трее иконку сервера и нажмите”. Но у меня нет трея, у меня на насе все!
Решил посмотреть, куда эта страничка лезет. Включил Web Developers tools и обнаружил, что скрипт довольно активно ломится на 127.0.0.1:32400. Ну-ка.. (тут пропущено немного мата и поисков, что же этой штуке надо). Итак, инструкция
Включаем в настройках Synology ssh сервер
Разблокируем пользователя admin (вы же его заблокировали, сразу как настроили, да?). Другие пользователи не подойдут, там хардкод.
ssh -L 32400:127.0.0.1:32400 admin@192.168.90.91 , где 192.168.90.91 адрес сервера
Ну и в браузере вводите http://127.0.0.1:32400 (Не localhost, plex тупой слишком).
Вуаля. Теперь вам открылась админка plex, где есть эта кнопочка claim.
Суть простая: у меня есть сеть с Н выходов наружу. И очень надо, чтобы весь трафик на gmail шел через определенный узел. Казалось бы, фигня вопрос! Берем AS gmail и зароучиваем куда надо. Но фиг-то там. Нет отдельной AS для почты. Там у них все в куче: и почта и ютюб и прочее.
Ок, давай 25й порт завернем … Но опять же, весь почтовый трафик не нужен! Остается только по адресам. Но и тут засада: они меняются. Не часто, но регулярно! Ок, пара минут (ладно, полчаса) и готов такой однострочник.
alias gmail="echo \"conf t\"; for i in {alt1.gmail-smtp-in.l.google.com.,gmail-smtp-in.l.google.com.,alt2.gmail-smtp-in.l.google.com.,alt4.gmail-smtp-in.l.google.com.,alt3.gmail-smtp-in.l.google.com.}; do host \$i 127.0.0.1 | grep has\ address | awk '{ print \"ip route \" \$4 \"/32 37.9.13.1\"; }' ; done; echo \"exit\"; echo \"write\"; echo \"exit\""
На момент написания результат будет такой
conf t
ip route 108.177.125.27/32 37.9.13.1
ip route 64.233.161.26/32 37.9.13.1
ip route 192.178.163.27/32 37.9.13.1
ip route 173.194.208.27/32 37.9.13.1
ip route 142.250.101.27/32 37.9.13.1
exit
write
exit
В результате все текущие почтовые адреса гмыла пойдут через 37.9.13.1 – это адрес роутера в селектеле, через который подключен мой сервер. Как этот вывод скормить FRR автоматично предлагаю решить самостоятельно 🙂
В прошлой части я писал про resident ключи. И вроде все работало. А теперь решил попробовать поработать с non-resident. И тут же столкнулся с тем, что хоть ssh-add и работал, но заходить на сервера не получалось. Если запустить ssh -v, то можно было увидеть строчки from agent: agent refused operation
Немного нагуглив, я нашел рецепт: дескать, ssh-agent нужно подтвердить, а ему не у кого. И дескать, лечится установкой ssh-askpass и правки скрипта, который пускает ssh-agent. Ок, правлю вот так:
Все остальное оставляю прежним. Грохаю все и пытаюсь зайти
...
debug1: Will attempt key: /Users/xxxxxx/.ssh/id_ed25519
debug1: Will attempt key: /Users/xxxxxx/.ssh/id_ed25519_sk
debug1: Will attempt key: /Users/xxxxxx/.ssh/id_xmss
debug1: Offering public key: xxxxxx@yyyyy.ru ED25519-SK SHA256:4GX39PbvB7LoXoBzPrxABAt5xC+x05y6WNtgW3qAN+A authenticator agent
debug1: Server accepts key: xxxxxx@yyyyy.ru ED25519-SK SHA256:4GX39PbvB7LoXoBzPrxABAt5xC+x05y6WNtgW3qAN+A authenticator agent
sign_and_send_pubkey: signing failed for ED25519-SK "xxxxxx@yyyyy.ru" from agent: agent refused operation
debug1: Offering public key: xxxxxx@yyyyy.ru ED25519-SK SHA256:W/dXsAitpJKpPcYNf2zB+ucsG+zx50R0hSzIQ2Lwl74 authenticator agent
debug1: Server accepts key: xxxxxx@yyyyy.ru ED25519-SK SHA256:W/dXsAitpJKpPcYNf2zB+ucsG+zx50R0hSzIQ2Lwl74 authenticator agent
debug1: Enabling compression at level 6.
Authenticated to 10.34.178.1 ([10.34.178.1]:22) using "publickey".
debug1: setting up multiplex master socket
...
В логах видно, что у меня два ключа. Первый я вынул и спрятал. А вот второй – на месте. Вот где я добавил пустую строчку – там он стал ждать прикосновения к ключу. Никаких запросов или там окошек всплывающих не появилось. Нафига нужен ssh-askpass? Не знаю. Я даже попробовал перезагрузиться и ключ вставить-вынуть – ничего не поменялось…
Долго ли, коротко, но в руках у меня снова оказался yubikey. Да, вот эта вот штука, которая устами манагеров обещает устойчивость ко взлому, фишингу и прочим ужасам современного ИТ-мира. Прошлый мой подход к юбикам окончился полной неудачей из-за кривого софта, драйверов и в общем-то моим нежеланием разбираться во всей этой мешанине букв и аббревиатур. Но тут отступать оказалось некуда, поэтому пришлось разбираться.
Итак, для начала. Если вы это делаете для себя, то берите минимум (подчеркиваю, минимум) два юбика. Дело в том, что юбики из-за природы своей не бекапятся, не обновляют прошивку и так далее и тому подобное. Если вам это вручили на работе, то вся боль по поводу работоспособности юбиков совершенно не ваша забота.
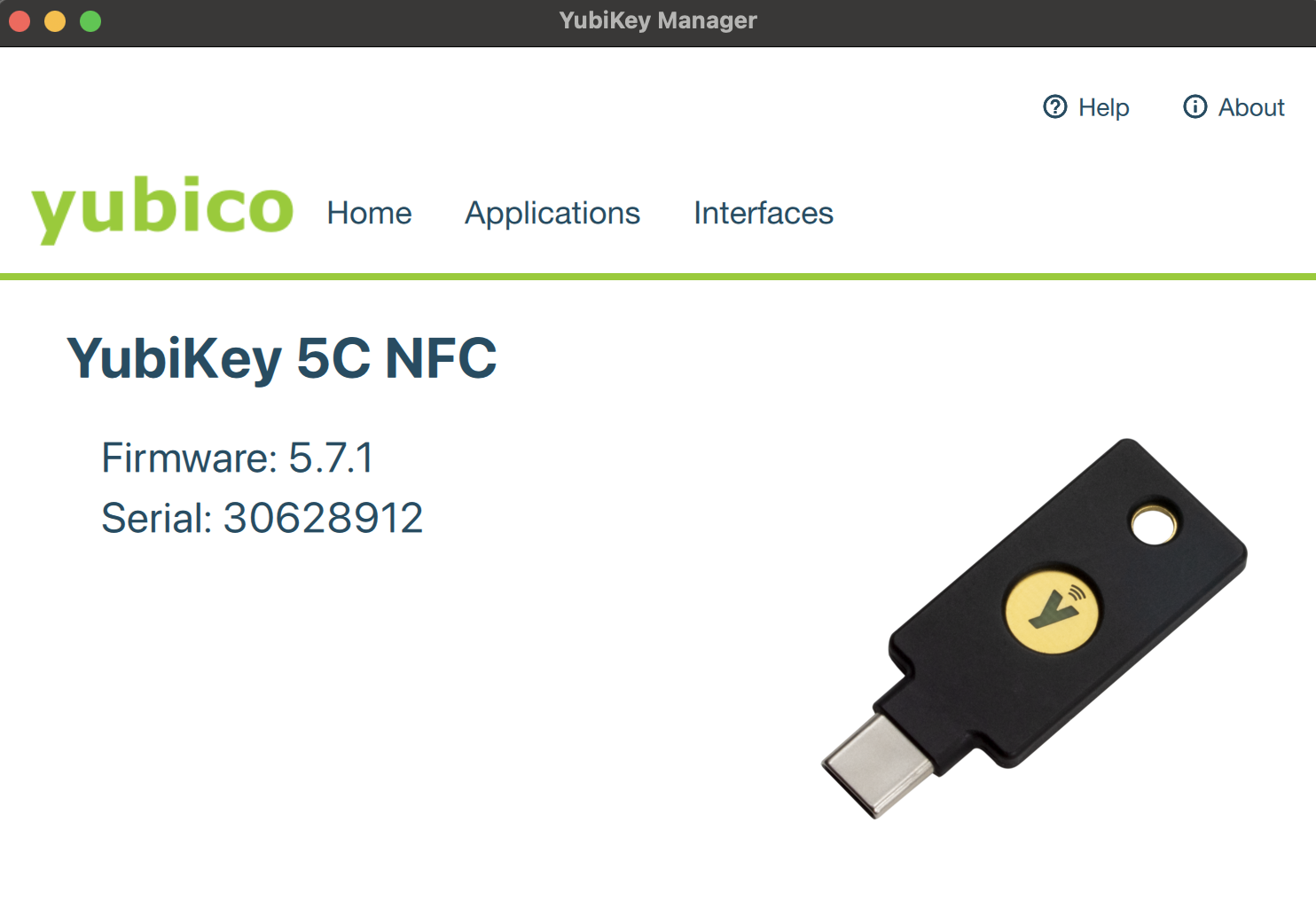
В общем, для начала надо заиметь свой юбик и поставить на комп Yubikey Manager. Ставим, запускаем, втыкаем ключ и вы должны увидеть что-то подобное этому:
Если увидели, то хорошо. Не увидели – дальше нет никакого смысла продолжать, надо разбираться, почему оно не алле.
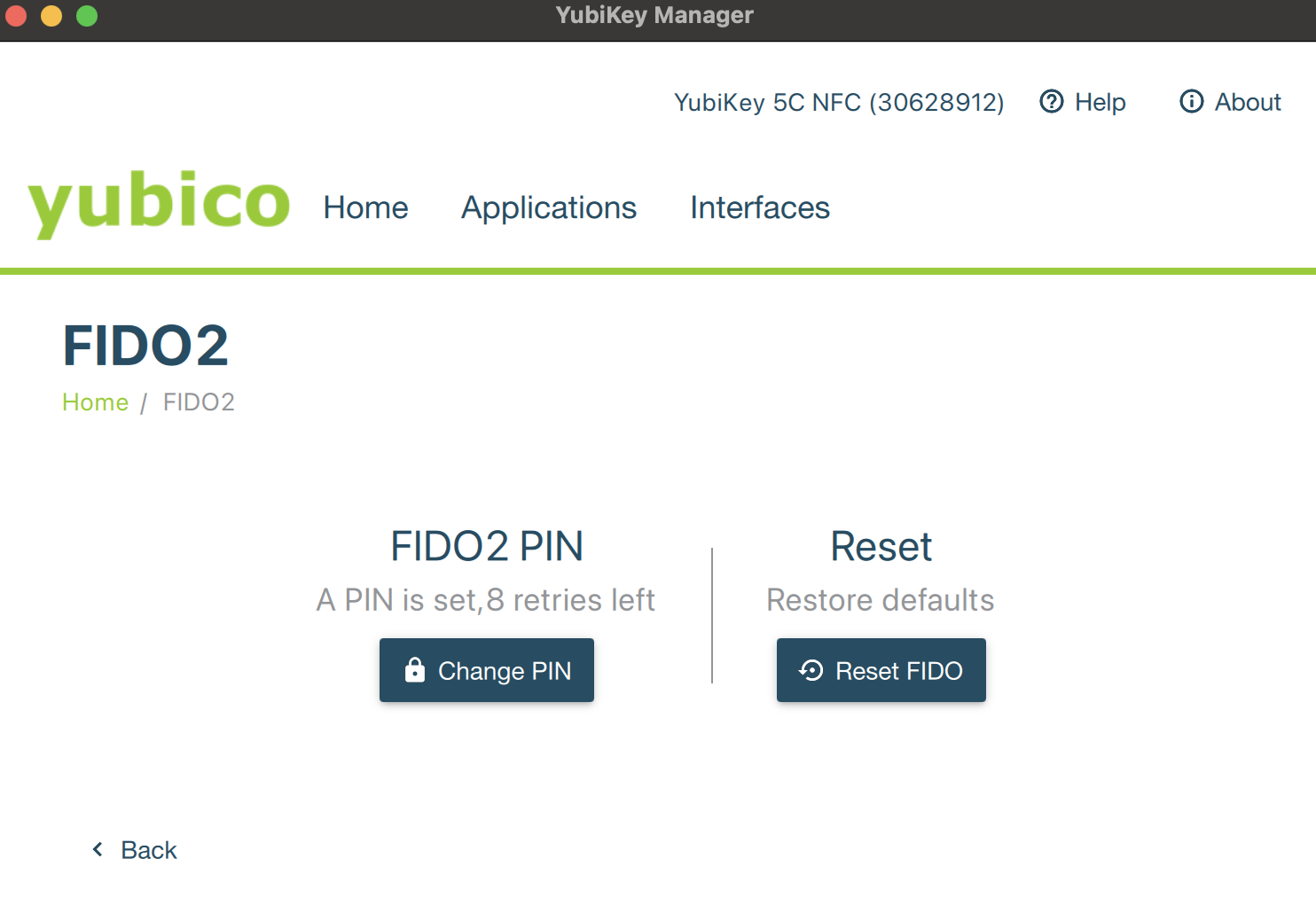
Так как я хочу для начала настроить ssh, то (тут пропущено часов Н чтения мануалов и страничек) сходить на вкладку Applications – FIDO2 и нажать на кнопачку Change Pin. Ибо стандартный пин 123456 совершенно не секурный и вообще. После смены пина должно получиться следующее:
Ну а теперь самое интересное: необходимо сделать новый ssh ключ. Старые не подойдут, но в общем-то и не очень и хотелось. И тут внезапно появляется выбор: какой ключ делать? Если по типу шифрования вопросов нет – только ed25519, то вот резидентный или не резидентный ключ генерить…
Немного погуглив, я выяснил, что Discoverable Credential или Resident ключ – это тот, который полностью хранится в памяти ключа. А вот Non-Resident – это хранение ключей как обычно, в файликах, но без юбика они бесполезны. В чем проблема? Если у вас resident ключ и у вас сперли юбик, то злой дядька хакер сможет ходить на ваши сервера как к себе домой. Надежда на пин-код слабая, ибо подсмотреть его как нефиг делать. А если у вас non-resident ключи, то вам нужно будет таскать файлики ключей по своим рабочим машинкам. Выбирать вам. Лично я тут топлю за non-resident.
Далее все совершенно стандартно. Генерим ключ (ВНИМАНИЕ! -O resident тут сами понимаете для чего)
ssh-keygen -t ed25519-sk -O resident
… И копируем получившийся id_ed25519_sk.pub по нужным местам. Тут процедура тоже совершенно стандартная и описана 100500 раз везде.
В общем-то почти все. Набираем ssh user@host и получаем… облом по полной. Полное впечатление, что ssh тупо завис. Однако это не так, ssh просто ждет касания ключа, только почему-то не пишет об этом. Если оно горит (мне нет), то опять гуглим. Оказывается, если у вас для ssh есть обычные ключи и они уже добавлены в ssh-agent (вот тут не уверен), то для нового ключа ssh ничего решает не спрашивать. Правим .ssh/config
И пробуем снова. У меня получилось и он стал спрашивать. Так как я делал resident ключ, то теперь радостно размахивая шашкой, удаляю все честно нагенеренное, имитируя новую машину. Или после ребута. Смотрим, какие есть ключи
Вот. ED25519-SK это тот, что “спрятан” в юбике. Пробуем ходить по ssh… ходится! На этом этапе можно начинать бросать чепчики в воздух и кричать “ура!”.
Ну и на всякий, ssh-keygen -K “вытащит” из юбика публичный ключ прямо в текущий каталог. Правда, получившийся приватный ключ получится фейковым non-resident и все равно, без юбика ничего работать не будет.
Вы не поверите, но снова подтвердилась теория о том, что компьютеры обладают душой. Стоило мне написать предидущий пост, как ubuntu совершила самоубийство. Я просто закрыл ноутбук и он больше не вышел из сна. И потом вообще отказался загружаться – даже груб не мог запуститься.
В общем, буквально пара дней и у меня появилась почти удовлетворяющая меня система. И более того, в случае чего я могу повторить ее буквально за несколько минут. Всякие мелочи типа скорости курсора и прочее пока приходится настраивать руками.
Внезапно (тм) я обнаружил, что пользователям, которые сидят за кинетиком, не достается ipv6. Хотя сам кинетик исправно получает ipv6 и отображает его в дашборде. Немного погуглив, я обнаружил, что одной подсетки /64 кинетику мало, ему надо еще отдать некий prefix description.
Итак, схема соединения простая router - keenetic - user.
Роутер совершенно честно получает 2001:db8:99:0:52ff:20ff:fe7d:5d71 и показывает этот же адрес у себя в дашборде. И вот тут у меня возник затык. Везде рецепты по получению этого самого PD приводили к каким-то шаманским пляскам с systemd-network и прочим вещам. Естественно, роутеру на это было совершенно монопенисуально. В итоге индеец зоркий глаз обнаружил, что ISC DHCPD умеет отдавать этот самый PD.
Я вырезал лишнее. Если кратко, то вся суть в последних трех строчках. DHCPD садится на интерфейс, содержащий адрес из подсети 2001:db8:99::/48 и говорит, что любой обратившийся может взять префикс /56 из диапазона 2001:db8:100:100-200
Перезапускаем и тут же получаем в логах следующее
Sep 04 14:36:19 router-wifi dhcpd[2060]: Rebind message from fe80::52ff:20ff:fe7d:5d71 port 546, transaction ID 0x4E15F400
Sep 04 14:36:19 router-wifi dhcpd[2060]: Reply PD: address 2001:db8:100:200::/56 to client with duid 00:03:00:01:50:ff:20:7d:5d:71 iaid = 1 valid for 150 seconds
Sep 04 14:36:19 router-wifi dhcpd[2060]: Sending Reply to fe80::52ff:20ff:fe7d:5d71 port 546
Идем в дашборд кинетика и видим появившуся строчку IPv6 prefix
И клиент тоже подтверждает, что он получил айпишник из этого префикса
2: wlp0s20f3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 68:3e:26:b0:b1:93 brd ff:ff:ff:ff:ff:ff
inet 192.168.1.128/24 brd 192.168.1.255 scope global dynamic noprefixroute wlp0s20f3
valid_lft 215sec preferred_lft 215sec
inet6 2001:db8:100:200:fd6c:e8a9:6e3:7d75/64 scope global temporary dynamic
valid_lft 134sec preferred_lft 84sec
inet6 2001:db8:100:200:ae30:1497:47c9:c0e7/64 scope global dynamic mngtmpaddr noprefixroute
valid_lft 134sec preferred_lft 84sec
inet6 fe80::8e0b:e946:d9e4:9dfd/64 scope link noprefixroute
valid_lft forever preferred_lft forever
И теперь самое сложное: дать роутеру понять, куда надо роутить трафик для 2001:db8:100: . Вот тут я нормальных решений не нашел. Кинетик не умеет в динамические протоколы роутинга, а городить некий парсер логов и потом править роуты мне стало откровенно лень. Как делают большие пацаны из телекомов я тоже не нашел. Поэтому я взял и захардкодил это в роуты
routes:
- to: "2001:db8:100::/48"
via: "2001:db8:99:0:52ff:20ff:fe7d:5d71"
on-link: true
Да, криво. Да, может сломаться, если кто-то еще в этой сети попросит PD. Но, повторюсь, других вариантов я не нашел.
Ну а дальше наслаждаемся нормальным ipv6 и прочими положенными плюшками
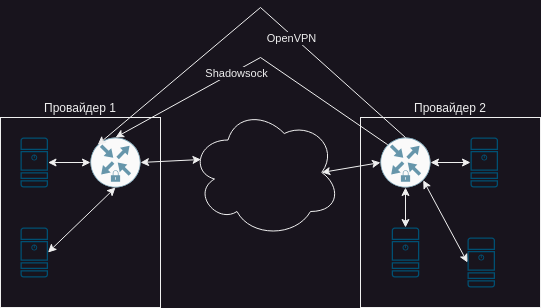
Недавно мне потребовалось соеденить две площадки с виртуалками. Обе у нас (ПОДЧЕРКИВАЮ!), обе у достаточно крупных провайдеров. В общем, надо сделать так, чтобы Н машин у одного провайдера видели М машин у другого. Трафик не большой, но достаточно критичный.
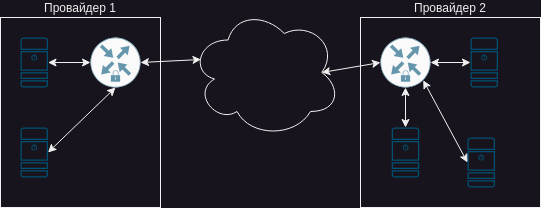
“ХА!” – сказал я и нарисовал классическую схему соединения.
Выделяем на каждой площадке машинку (или на одну из доступных вешаем внешний ip), обвешиваемся файрволами и закрываем трафик тем же IPSec. Инструкций много, вариантов много – в общем, прорвемся!
Быстренько собрал, накидал конфиги и получил веслом по морде. Протокол ESP где-то по пути заблокирован. Техподдержка обоих провайдеров клянется, что это не у них, но ipsec не верит и отказывается подниматься. Ладно, хотелось по-корпоративному, пойдем по-молодежному.
OpenVPN шустро поднялся, поначалу начал бодро гонять трафик, но через некоторое время начались проблемы. Он переподсоединялся, слал немного байт и снова уходил в нирвану. Смена протокола с UDP на TCP приносила лишь временное облегчение.
Кто виноват – мне, если честно говорить, абсолютно пофиг. Мне трафик нужно гонять. Поэтому расчехлил тяжелую хипстерскую артиллерию – shadowsocks + v2ray. Качаем с гита, просто распаковываем, плюем в конфиг сервера следующее (1.1.1.1 – это внешний адрес сервера, если что):
Запускаем и получаем на клиенте socks5 сервер на 1080 порту. А теперь – финт конем. В конфиг OpenVPN на клиенте добавляем одну единственную строчку:
socks-proxy 127.0.0.1 1080
Ну и перезапускаем все, чтобы прочитало конфиги. Вуаля! У нас получилась следующая схема:
OpenVPN ходит через ShadowSocks, который ходит через хрен знает как настроенный интернет.
Но через некоторое время проявилась та же самая боль: немного погодя клиент терял соединение с сервером. Причем перезапустишь – все снова начинает бегать. Ставил опции ping, менял MSS и MTU – пофиг: рандомно теряем коннект.
Ок, перевел openvpn и shadowsock на TCP. Всё магически исправилось. Коннект стабильный, не рвется, пакетики бегают туда-сюда.
Отключил "mode": "tcp_and_udp", позакрывал фаирволлами и начал тестить.
Итак, прямой tcp линк безо всяких штук
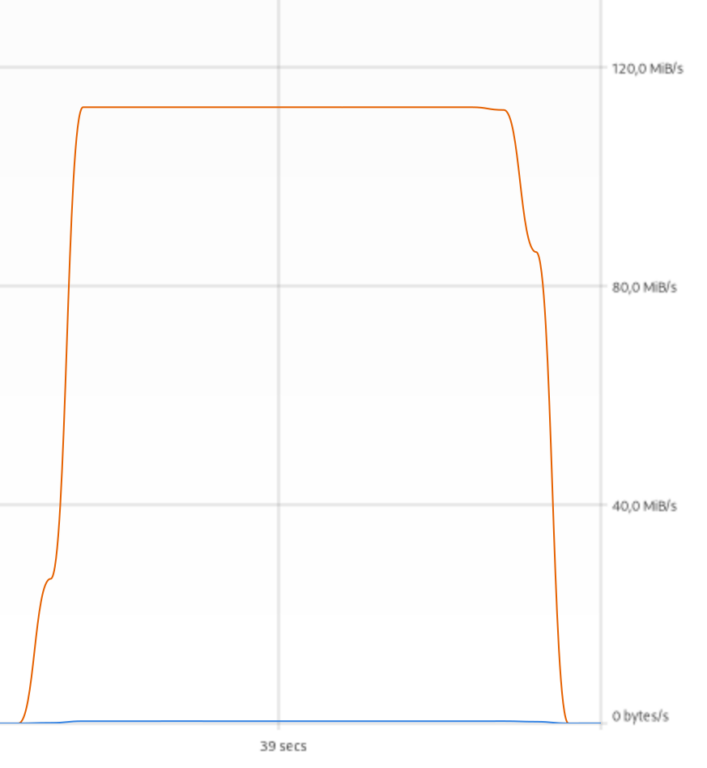
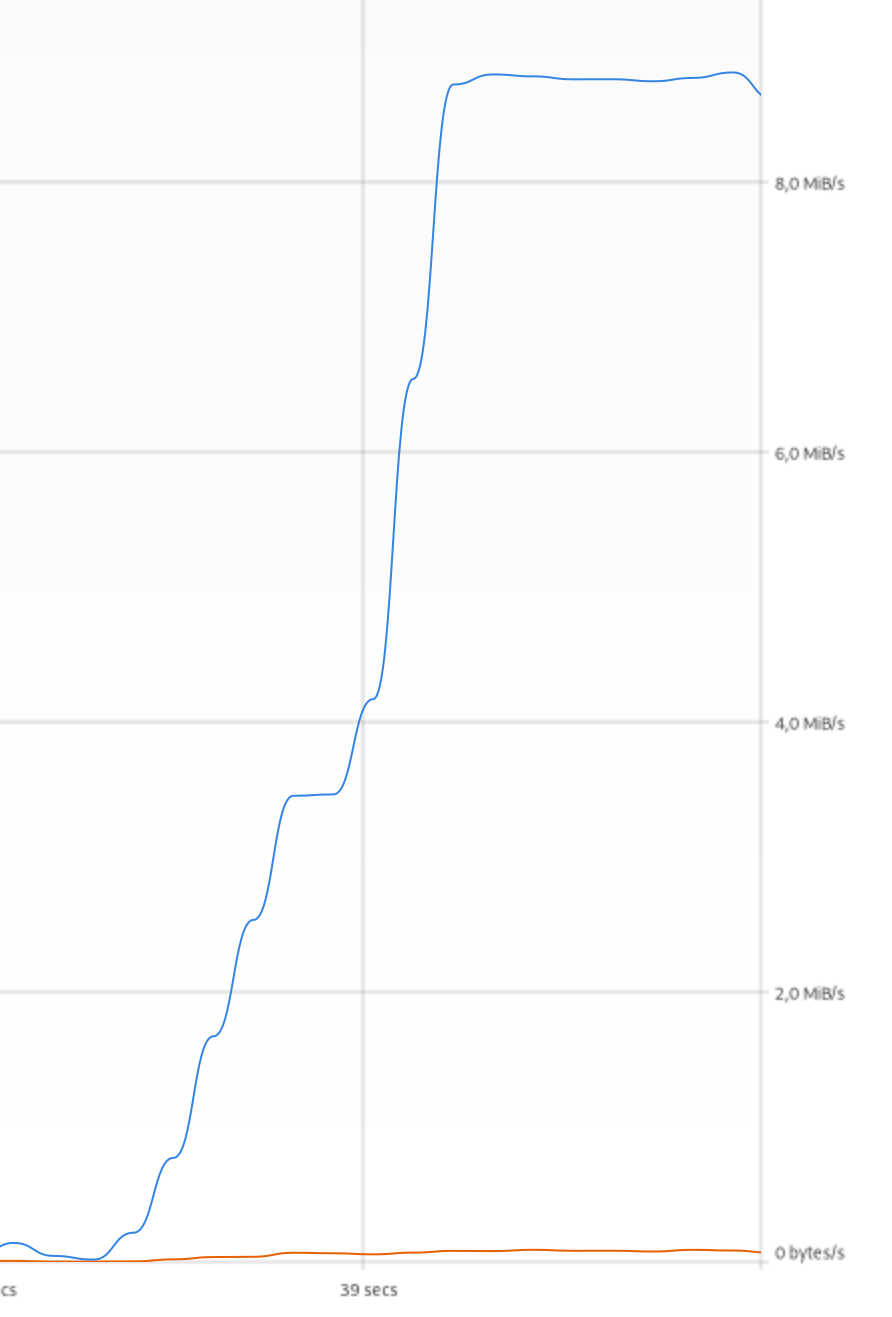
[ 1] 0.0000-10.2561 sec 112 MBytes 91.8 Mbits/sec
Да, клиент сидит на дешевом тарифном плане в 100 мегабит, поэтому практически упираемся в полку. Теперь через все эти навороты:
И это без какого-либо тюнинга! Да, tcp-over-tcp-over-tcp еще тот изврат, но ведь работает же! А после тюнинга (банальные буфера и прочее – в любом мануале по openvpn) я получил следующее:
Нам надо платить меньше. На одной стороне не нужен выделенный ip (а они нынче дорогие). Выпускают всех через SNAT и норм.
Настраивается не просто, а очень просто.
Снаружи на сервере порт OpenVPN можно спокойно закрыть фаирволлом. Соединение идет с локалхоста. Больше сесуретей богу сесурити!
Память не жрет. Можно смело брать самую дешевую виртуалку под “роутеры”. Вся вот эта машинерия + FRR с OSPF сьели 200 мегов.
Оно работает. Реально, за неделю уже не одиного разрыва.
Что в минусах:
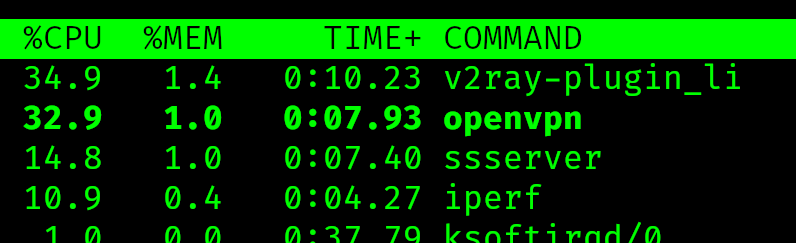
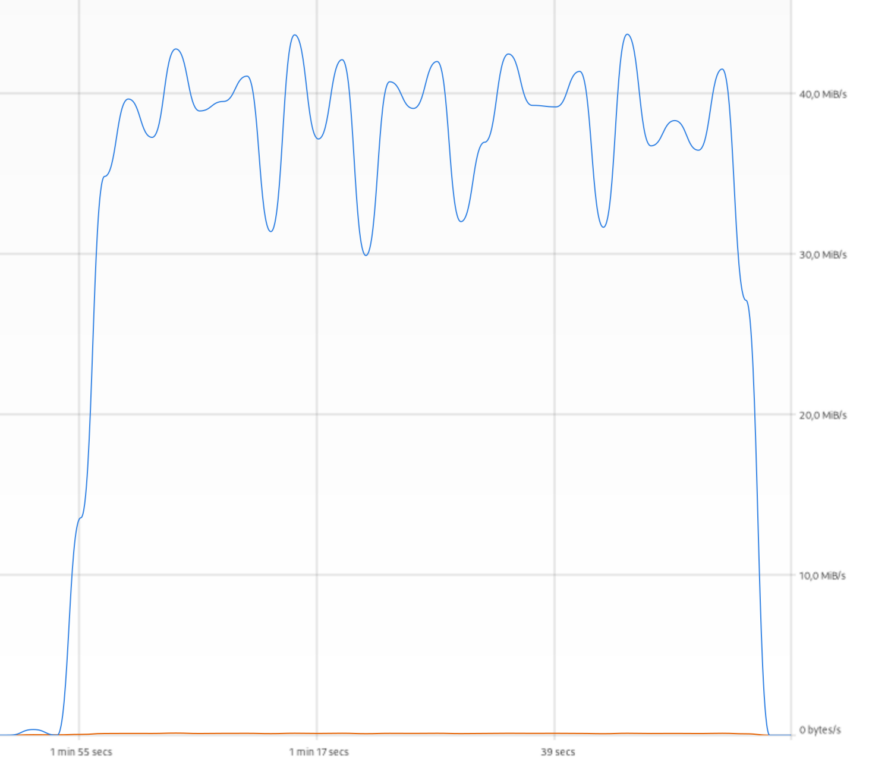
Потеряли в скорости. Немного, но есть. Проблема в том, что на стороне клиента я банально уперся в единственный ЦПУ виртуалки. Когда тесты идут, на той стороне в топе такое:
С другой стороны, там трафик в 20-30 мегабит уже редкость, так что в любом случае все в порядке. Но запас карман не тянет.
Ну и нафига я все это делал: мне нужно было среплицировать один MySQL в другой. Предложенная схема их удовлетворила, значит задача выполнена.
Поначалу я планировал этот пост про InfluxDB. Дескать, вот так поставим, вот так настроим… Однако реальность больно тыкнула вилкой в глаз: поставил, запустил, зашел на influx:8086, установил пароль, завел организацию… и всё. Нет, реально всё. Больше там ничего не потребовалось делать.
А вот с телеграфом пришлось повозиться. Дело в том, что я возжелал с одной машины отправлять разные метрики в разные бакеты. Ну всякие там “загрузка процессора и памяти” в один, а “температура в доме” – в другой. Ну вот захотелось мне так.
Все просто. Для начала прямо в telegraf.conf добавим тег influxdb_database
# Global tags can be specified here in key="value" format.
[global_tags]
# dc = "us-east-1" # will tag all metrics with dc=us-east-1
# rack = "1a"
## Environment variables can be used as tags, and throughout the config file
# user = "$USER"
influxdb_database = "default"
Да, я очень неоригинален в этом плане. Теперь ко всему, что собирает telegraf по умолчанию добавляется тэг influxdb_database со значением default.
Теперь добавляем сборку данных с mqtt. Заполняем файл /etc/telegraf/telegraf.d/mqtt.conf
[[inputs.mqtt_consumer]]
servers = ["tcp://127.0.0.1:1883"]
## Topics that will be subscribed to.
topics = [
"/devices/+/controls/temperature",
"/devices/+/controls/battery",
"/devices/+/controls/humidity",
"/devices/+/controls/pressure",
"/devices/+/controls/co2",
"/devices/+/controls/MCU Temperature",
"/devices/+/controls/CPU Temperature",
"/devices/dark_room_power/controls/voltage",
"/devices/dark_room_power/controls/power",
"/devices/sleeping_room_power2/controls/voltage",
"/devices/sleeping_room_power2/controls/power",
]
data_format = "value"
data_type = "float"
[inputs.mqtt_consumer.tags]
influxdb_database = "mqtt"
Тут тоже все просто: указываем адрес сервера, указываем, на какие топики подписаться, их формат и последней строчкой меняем значение тега на mqtt. И теперь самая магия:
Наверняка для матерых инфлюксоводов это покажестя легкой шуткой, но я честно потратил пару часов на раскуривание функционала tagpass. Больше, правда, на выяснение, как и куда его правильно прописать. В общем, теперь все с influxdb_database = default попадает в бакет hlevnoe, а mqtt в mqtt.
Запустив все это и убедившись в отсутствии ошибок, можно вернуться в influx. Там есть простенький data explorer, позволяющий потыкаться и порисовать графики. Даже можно простейшие дашборды собрать!
Вот, к примеру, график потребления электричества у морозильника.
Или график температуры у меня за окном
В общем, это далеко не графана, но по-быстрому позырить что к чему – можно.
Умная мысля приходит обычно слишком поздно. Вот и тут, я много лет страдал при переходе с одного компа на другой. В каждой операционке своя терминалка, со своими дрючками и глючками. Я ходил, настраивал и пытался их подогнать одну к другой.. Хорошо еще, что хоть чуть-чуть шорткаты устаканились, а то вообще боль была…
В общем, я решил сменить терминалку. Немного подумал и составил офигенно длинный лист требований:
Терминалка должна работать под Linux, MacOS и Windows (WSL)
Она должна работать одинаково. То есть один и тот же параметр в конфиге должен приводить к одним и тем же изменениям в поведении.
Терминалка должна уметь в truecolor.
Терминалка должна уметь в шрифтовые лигатуры.
Всё остальное, типа рендеринга на GPU или особо правильной поддержке многих систем, мне было совершенно не нужно. Главное, чтобы я взял ноутбук на другой операционке и получил абсолютно тот же… сейчас это модно называть экспириенсом. Внезапно самым сложным для терминалок оказался последний пункт.
Я не понимаю, чего сложного в подобной конвертации символов -> >> <> != ? Но, например, авторы gnome terminal не осилили подобного и отмазались, что не для всех языков это может работать. Ну сделали бы не для всех…
И, внезапно, всем моим хотелкам удовлетворила только одна терминалка – kitty. Если быть до конца честным, то нет, были и другие, но они не такие гламурные. Ставить котёнка можно 100500 способами, но я предпочел через пакетный менеджер.
После установки я некоторое время испытывал реальную боль. Дело в том, что автор этой терминалки – индус и очень своеобразно подошел к составлению документации. Кусочек тут, кусочек там, а потом можно и вот сюда глянуть… В общем, вот мой конфиг
Последние строчки – это дань моей лени, чтобы новые окошки открывались как на макоси. Win+n и не надо пальцы ломать об Ctrl+Shift+n . Мелочь, а удобно. Ну и файлик theme.conf, честно спертый из интернета и имитирующий тему homebrew
И вот я уже почти неделю живу на двух операционках и с одним терминалом. Нормально …
Теперь операционко-специфичные штуки.
MacOS: надо в ENV переменные добавить KITTY_CONFIG_DIRECTORY=~/.config/kitty/ , иначе котенок хз где хранит конфиги. А так все в одинаковом месте. Чтобы сменить иконку, надо ее просто рядом с конфигом положить и обозвать kitty.app.png.
Linux: чтобы сменить иконку, надо сделать desktop файл, аналогичный нижеприведенному, и положить его в .local/share/applications/ . Главная боль – путь до иконки должен быть абсолютным.
Пора, пора описывать то, что было сделано. А то как обычно, забудется и всё, пиши “прощай”.
Итак, давным-давно, когда ещё существовала страна под названием “Украина”, я начал делать свою… Ну даже не знаю, на лабораторию это не тянет, на свой датацентр тоже. В общем, несколько серверов, выполняющих нужные для меня задачи. Часть арендованные, часть свои… И всё было совсем хорошо, пока не началась СВО. Тут же вылезла куча говна и давай блочить доступ. Следом к ним присоеденились убегуны и давай портить до чего руки дотянутся. Дескать, они все такие чувствительные, что не могут позволить такое и вааще, они только за самое хорошее! Но тут не про них, а про то, как сделать себе хорошо и нагло игнорировать подобное сейчас и в будущем.
Итак, условия для этой задачи и последующих простые: я должен иметь возможность поставить или обновить нужное мне в любой момент времени. Есть интернет, нету – все равно. И первым шагом я сделаю зеркало для пакетов дистрибутива ubuntu.
Погуглив, я нашел несколько инструкций, как сделать свое зеркало. Немного потыкался в монстров типа Nexus и прочих JFrog и решил, что лучшее враг хорошего. Итак, для начала нам нужна машинка с более-менее приличным диском. Далее все просто и прямолинейно: ставим необходимое и подготавливаем структуру каталогов
А вот теперь скрипт, который все друг у друга таскают. Я не исключение
# cat > debmirroramd64.sh
#!/bin/bash
## Setting variables with explanations.
#
# Don't touch the user's keyring, have our own instead
#
export GNUPGHOME=/mirror/debmirror/mirrorkeyring
# Arch= -a # Architecture. For Ubuntu can be i386, powerpc or amd64.
# sparc, only starts in dapper, it is only the later models of sparc.
# For multiple architecture, use ",". like "i386,amd64"
arch=amd64
# Minimum Ubuntu system requires main, restricted
# Section= -s # Section (One of the following - main/restricted/universe/multiverse).
# You can add extra file with $Section/debian-installer. ex: main/debian-installer,universe/debian-installer,multiverse/debian-installer,restricted/debian-installer
#
section=main,restricted,universe,multiverse
# Release= -d # Release of the system (, focal ), and the -updates and -security ( -backports can be added if desired)
# List of updated releases in: https://wiki.ubuntu.com/Releases
# List of sort codenames used: http://archive.ubuntu.com/ubuntu/dists/
release=noble,noble-security,noble-updates,noble-backports
# Server= -h # Server name, minus the protocol and the path at the end
# CHANGE "*" to equal the mirror you want to create your mirror from. au. in Australia ca. in Canada.
# This can be found in your own /etc/apt/sources.list file, assuming you have Ubuntu installed.
#
server=ru.archive.ubuntu.com
# Dir= -r # Path from the main server, so http://my.web.server/$dir, Server dependant
#
inPath=/ubuntu
# Proto= --method= # Protocol to use for transfer (http, ftp, hftp, rsync)
# Choose one - http is most usual the service, and the service must be available on the server you point at.
# For some "rsync" may be faster.
proto=rsync
# Outpath= # Directory to store the mirror in
# Make this a full path to where you want to mirror the material.
#
outPath=/mirror/debmirror/amd64
# By default bandwidth is not limited. Uncommend this variable and set it to the apropriate
# value in Kilobytes per second. Also don't forget to uncomment the --rsync-options line in the last section below.
bwlimit=1000
# The --nosource option only downloads debs and not deb-src's
# The --progress option shows files as they are downloaded
# --source \ in the place of --no-source \ if you want sources also.
# --nocleanup Do not clean up the local mirror after mirroring is complete. Use this option to keep older repository
# Start script
#
debmirror -a $arch \
--no-source \
-s $section \
-h $server \
-d $release \
-r $inPath \
--progress \
--method=$proto \
--rsync-options "-aIL --partial --bwlimit=$bwlimit" \
$outPath
Скрипт настроен на российский миррор и лимит в 1 мегабайт в секунду, чтобы не забивать канал, как минимум при первоначальной скачке. Ну и релиз поменял на noble, ибо нынче уже 2024 год и в ходу у меня 24.04. Далее просто запускаем этот скрипт и идем заниматься своими делами. Оно медленно и печально высосет кучу гигабайт. Реально КУЧУ гигабайт. На момент написания размер зеркала был в районе двухсот гигов.
Ну а дальше просто везде разбрасываем новый ubuntu.list, заменяя им ubuntu.sources
deb http://mirror/ubuntu noble main restricted universe multiverse
deb http://mirror/ubuntu noble-security main restricted universe multiverse
deb http://mirror/ubuntu noble-updates main restricted universe multiverse
И точно так же миррорим что-то другое. К примеру, возжелал я поставить InfluxDB. Можно пакетики тащить, а можно зеркало сделать.
И чуточку поправленный скрипт без комментариев. Изменил только откуда брать, куда ложить и то, что не надо использовать rsync. Адреса и прочее я нагло упер из инструкции с официальной страницы https://www.influxdata.com/downloads/, когда выбрал Ubuntu&Debian
С чего начинается любой умный дом? Ну в смысле если он действительно претендует на право называться умным? Правильно, с места хранения состояния всяких устройств и датчиков.
Исторически сложилось, что для централизации подобного используется протокол MQTT. Он легкий, простой и поддерживается всеми участвующими в деле устройствами.
Вообще у меня уже есть один mqtt сервер, встроенный в wirenboad. Но есть два больших но: 1) сам по себе wirenboard очень дохлый (хотя народ радостно на него даже Home Assistant в докере водружает) и 2) у меня будет очень много устройств, общающихся по MQTT.
Поэтому решение простое: поднимаем на виртуалке MQTT сервер и заставляем всех с ним работать. А кто не умеет или умеет не кошерно – забирать с тех данные самим. Для реально больших нагрузок или отказоустойчивости народ ставит EMQX, но у меня такого не будет, поэтому использую mosquitto.
apt install mosquitto mosquitto-clients
Все настройки оставляю по умолчанию, просто добавляю один мост wirenboard->mosquitto.
Принцип простой: тупо подписываемся на все топики с сервера wirenboard. Паролей и логинов нет, всяких TLS тоже не наблюдается. Проверить работоспособность полученного решения тоже проще простого:
mosquitto_sub -t \#
Если все хорошо, то вы должны увидеть бегущую колонку цифр. Wirenboard сам по себе генерирует кучу трафика, так что никаких пауз не будет. А если у вас, как и у меня, уже подключены датчики, то трафик становится довольно большим для глаз.
Дело было как-то вечером. Есть у меня дома контроллер wirenboard. Пока идет знакомство, наладка и отстройка, управляет светом около стола, да и меряет температуру по всему дому. Но не суть. наткнулся я на одну интересную багофичу: если пощелкать переключателями, а потом тут же обрубить питание, то эти самые переключатели после загрузки окажутся в рандомном состоянии.
Небольшое расследование со службой поддержки wirenboard показало, что дело в одном маленьком файлике. Вернее с тем, как linux с ним обращается. Верхнеуровневый софт честно в него пишет нужное, а вот линукс, желая сберечь ресурс emmc, начинает активно кешировать и сбрасывает файловый кеш тогда, когда в 99% уже поздно.
Казалось бы, фигня вопрос: засунь в крон sync и дело в шляпе. Ок, не в крон, это перебор, а после inotify и всё. Но сбрасывать всю FS ради одного файла… В общем, рецепт ниже.
# cat /etc/systemd/system/libwbmqtt-saver.service
[Unit]
Description=Drop file cache for libwbmqtt.db if it changed
[Service]
ExecStart=/bin/bash -c 'inotifywait -qq -e modify /var/lib/wb-mqtt-gpio/libwbmqtt.db && dd of=/var/lib/wb-mqtt-gpio/libwbmqtt.db oflag=nocache conv=notrunc,fdatasync count=0 status=none'
Restart=always
[Install]
WantedBy=multi-user.target
Всё написано на скорую руку, но тем не менее, прекрасно работает. Вся магия в том, что dd открывает фаил на запись, записывает 0 байт и закрывает, сбрасывая кеш. Такую оптимизацию подсмотрел где-то в инете, мое первоначальное решение было гораздо страшнее (и нет, не покажу).
… на вшивость. Или как проверить, что вам дают ровно столько интернета, сколько положено по тарифному плану.
В самом начале обязан раскрыть спойлер. Если обнаружится, что вам не докладывают интернета, то вы с этим ничего сделать не сможете. Ну разве что в воздух поорать чаечкой или попробовать счастья у другого провайдера. Техподдержка будет отвечать, что все в порядке и вообще так и должно быть. В общем, у вас просто нет никаких ручек для изменения ситуации.
Итак, для начала первый и единственный признак, что вам дают мало интернета: качается медленно. Но слово “медленно” очень субьективное, а нам нужна обьективность.
Итак, пойдем проверять по шагам:
Шаг первый: проверить вашу линию и устройства на ней. Ну сколько она может переварить в нынешних условиях. Откройте на том устройстве, на котором медленно, сайт speedtest.net. Почему именно его? Причина простая: все провайдеры в курсе этого сайта и специально оптимизируют свою инфраструктуру под него. Так что показанное значение скорости можно считать максимальным для данных условий.
Проверять лучше всего ранним утром и в выходные. Или хотя бы несколько раз в разное время. Причина простая: разные люди качают разное и вы вполне можете начать делить вышестоящий канал.
Когда не надо волноваться: показометр скорости интернета регулярно показывает 85% и больше от вашего тарифного плана. Иначе говоря, если у вас тарифный план в 300 мегабит, то увидеть вы должны 260 мегабит и больше. И да, на скорость исходящего трафика особого внимания можете не обращать.
Когда надо волноваться: во всех остальных случаях. Причин может быть множество: от дохлого роутера до забитого диапазона WiFi. К сожалению, лечение по фотографии тут невозможно, поэтому найдите и пригласите того, кто умеет в компьютеры.
Шаг второй: проверяем реальную скорость. Просто берем, гуляем по интернету и качаем большие файлы. Лично я по роду увлечений иду и качаю дистрибутивы линукса. Они в меру большие, часто лежат на отдельных серверах с хорошим каналом и поэтому вполне себе подходят под такое использование.
Что не надо делать: использовать большие и популярные сайты для скачивания. Причина простая: на них обычно ограничивается скорость скачивания для одного клиента.
Для визуализации очень полезно использовать монитор загруженности системы. В windows его можно позвать по комбинации клавиш Ctrl-Shift-Esc. В MacOS он в папке Утилиты, ну а линуксоиды сами знают, где его найти.
Опять же, когда не надо волноваться: файлики качаются быстро. Скорость, которую показывает браузер или монитор, очень похожа на то, что обещает провайдер. Редкие закачки, на которых скорость не растет – сорян, но это не показатель. Интернет на самом деле так устроен.
Когда надо волноваться: что бы вы не качали, откуда бы не пробовали – всегда скорость низкая.
Для примера визуализация, когда все идеально: и канал свободный и сервера не загружены и ваш компьютер не тормозит.
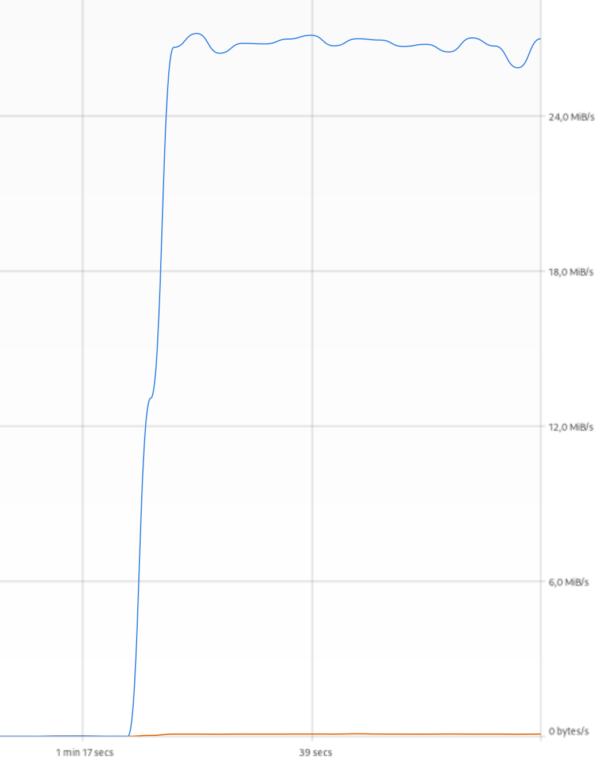
Для начала обратите внимание на уровень крутизны левой границы. Чем она вертикальнее, тем свободнее канал. Ну или если говорить другими словами, тем меньше расстояние до сервера, откуда вы качаете. Верхняя “полочка” своей ровностью говорит о том, что скорость что-то ограничивает. В данном случае – ограничение канала. Он просто физически быстрее не умеет передавать данные. Картинка ниже показывает, что сервер далеко (скорость растет гораздо медленней), но тоже упирается в какие-то внешние ограничения.
А теперь картинка, которую вы должны видеть в 99% случаев.
Скорость растет и потом начинает “колбаситься” возле верхней границы тарифа. Такое поведение абсолютно нормальное. В интернете постоянно летают туда-сюда тонны данных, маршруты перестраиваются, оборудование провайдера ограничивает вашу скорость согласно тарифному плану и так далее.
И теперь самое обидное, в общем-то ради чего и был написан этот пост. Случай, когда вам специально ограничивают скорость интернета. Провайдер, чужой сервер, инопланетянин – вам все равно, ибо вы никак это не контролируете.
На что тут необходимо обратить внимание?
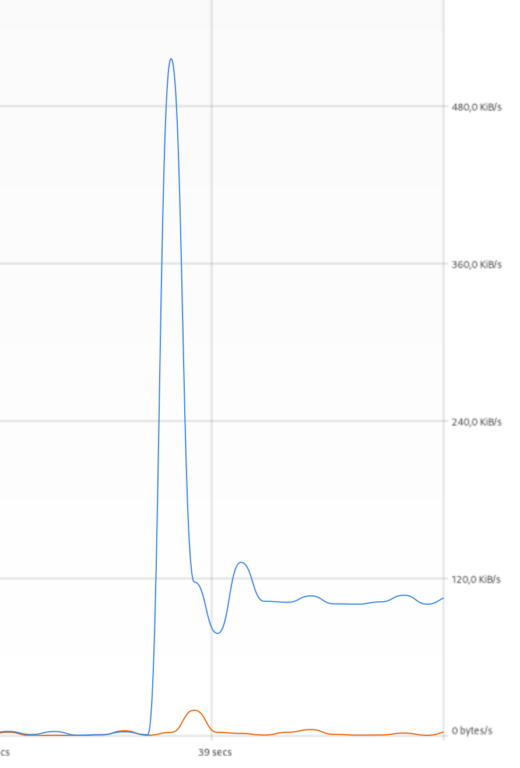
Скорость загрузки далека от возможностей канала и тарифного плана. Но повторюсь, это не абсолютный признак – может, просто сервер далеко или перегружен.
Верхний левый угол всегда содержит пик вверх, а следом яму. Вот это уже 100% признак ограничения скорости. Суть в том, что все ограничители настраивают по одной схеме: всегда есть какой-то объем данных, отдаваемых на максимальной скорости. Это очень помогает улучшить “отзывчивость” интернета. Следом яма – это ограничитель скорости понимает, что клиент вылез за границы и необходимо его “вогнать” лимиты. Высота пика и ямы может быть разная (сравните картинки выше) – это зависит от настроек шейпера.
“Расколбас” скорости дальше гораздо меньше, чем при нормальном скачивании. И он никогда не перепрыгивает первый пик. При “злых” ограничителях расколбас вообще исчезает.
Что можно сделать? Ну в общем-то только абсолютно банальные вещи:
Все-таки проверьте свое оборудование и условия, в котором оно работает. Как бы вы не были уверены, но и на старуху бывает проруха. Покачайте файлики локально, погоняйте тесты.
Смените сервер, откуда качаете. Совсем не факт, что выбранный (по расстоянию, национальной принадлежности и прочему) самый быстрый.
Пожалуйтесь в техподдержку провайдера. Может, вы просто чего-то упустили? Например, на всех “безлимитных” тарифных планах сейчас есть приписка мелким шрифтом, что можно скачать столько-то, а дальше либо скорость режут, либо вообще в инет не пускают. Вполне вероятен ваш случай.
Пожалуйтесь в соцсетях, с обязательным упоминанием провайдера. Это задействует совершенно другой канал коммуникаций с техперсоналом. Да, идиотизм, но это иногда работает
После какого-то обновления мой ноутбук стал плохо соединяться с Wifi. Ну как плохо… Регулярно стал терять сеть, ругаться на то, что не может соедениться и так далее и тому подобное. Так как у меня идет ремонт и я регулярно перетряхиваю сеть, то я грешил на точки доступа, линукс-сервер, выступающий роутером и на прочее, что могло повлиять.
Однако через некотрое время индеец зоркий глаз стал замечать, что на WiFi жалуется только ноутбук на Fedora. Windows, MacOS и андроиды и iOS цеплялись хорошо и никаких призывов не выдавали. И это бы продолжалось еще долго, но вчера линукс сказал “все, я больше не хочу соединяться с сетью”. Совсем.
Симптомы простые: ноутбук видит WiFi, соединяется, но через 45 секунд происходит тайм-аут DHCP и он отсоединяется. Установка статического адреса не помогает. Он перестает отваливаться, но пакеты никуда не ходят.
Проверка с помощью tcpdump показала, что в общем-то на это есть резоны: в канале было тихо. Причем настолько тихо, что даже запущенный с ноутбука ping не было видно. Тут я наконец-то понял, что проблемы именно на моей стороне.
Первым делом я решил, что проблема в сетевой. Воткнул USB, она со второго или третьего раза зацепилась. Тут бы мне насторожиться, но я пропустил этот момент. Начал играться с настройками WIFi на роутере. Ну так отключать/включать MIMO и прочее. Не помогло.
Включил точку доступа на телефоне. Ноутбук мгновенно прицепился и сообщил, что все в порядке.
То есть у ноутбука проблемы именно с моей точкой доступа. Стал разбираться. Ни каналы, ни смены настройки меш-сети – ничего не помогало. В веб-панели роутера я видел, что ноутбук соединяется и потом через некоторое время отваливается.
Так я сделал вывод, что железная часть работает. Дело в софте. И тут мне повезло запустить еще раз tcpdump как раз во время той самой паузы до таймаута. И внезапно я увидел бегающие туда-сюда пакетики, характерные для любой сети. Точно софт!
Стал разбираться. Оказалось, что добрые идиоты, пишущие Network Manager, где-то налажали в последних апдейтах и теперь мак-адрес меняется так, что он вводит сетевую в кому (или что-то еще в потрохах, но разбираться было лень). Ок, значит проблема простая: надо найти, где это выключается и дело в шляпе!
А вот тут возникла проблема. Оно нигде не выключается. Все найденные рецепты про wifi.cloned-mac-address и ethernet.cloned-mac-address не дали ровном счетом ничего. Повторяю: николай, иван, хартон, ульяна, яна. Так как дело было вечером, я решил не мучаться и вернуться на шаг назад. Говоря другими словами, вырубить нафиг NetworkManager.
Первым делом отвязываем wpa_supplicant от NM, хардкодим интерфейс и выключаем сам NM
Продолжаю делать записи для себя. На этот раз потребовалось отфильтровать роуты, отдаваемые другим. OSPF для этого не подходит: стандарт такого попросту не предусматривает. Значит, переключаемся на BGP. Минимальный конфиг для FRR
На другой стороне есть адрес 6.7.8.9, котрый не должен попасть на этот роутер.
!
ip route 6.7.8.9/32 10.1.0.254
!
router bgp 65000
bgp router-id 10.0.0.3
no bgp ebgp-requires-policy
neighbor 10.0.0.2 remote-as 65000
!
address-family ipv4 unicast
redistribute connected
redistribute static
neighbor 10.0.0.2 next-hop-self
neighbor 10.0.0.2 prefix-list nobad-out out
exit-address-family
exit
!
ip prefix-list nobad-out seq 5 deny 6.7.8.9/32 le 32
ip prefix-list nobad-out seq 10 permit 10.1.0.0/24 le 32
!
Проверяем
router2# show ip route bgp
Codes: K - kernel route, C - connected, S - static, R - RIP,
O - OSPF, I - IS-IS, B - BGP, E - EIGRP, N - NHRP,
T - Table, v - VNC, V - VNC-Direct, A - Babel, F - PBR,
f - OpenFabric,
> - selected route, * - FIB route, q - queued, r - rejected, b - backup
t - trapped, o - offload failure
B>* 10.1.0.0/24 [200/0] via 10.0.0.3, ens19, weight 1, 00:16:06
ВНИМАНИЕ: правка “на живую” permit-list не приведет к перечитыванию правил на другой стороне. Надо вручную в router bgp прицепить-отцепить их. Почему так – хз.
Вариант лечения: не важно где сказать clear ip bgp 10.0.0.3 (ессно, на передатчике адрес приемника и наоборот), это сбросит сессию bgp и заставит перечитать роуты.
В целях покупки домика загорелось мне устроить видеонаблюдение. И чтобы потом как в фильмах “вот преступник, увеличь кадр. еще! ага, попался!”. У меня преступников не ожидается, но хотелку осуществить очень охота.
И в процессе погружения в мир видеонаблюдения оказалось, что все в нем совсем не так просто. Вернее наоборот, просто, но совершенно перпендикулярно сознанию обычного ИТшника.
В начале было самое простое: система будет аналоговая или цифровая? В пользу первой говорит ровно два фактора: сейчас она очень (подчеркиваю очень) дешевая и она базируется на отработанных решениях. Все давно изучено, вылизано и понятно. Самое простое решение: купить валяющийся на складе готовый комплект, раскидать кабеля и успокоиться.
Но у аналогов есть и минус: от каждой камеры нужен прямой кабель до регистратора. 16 камер? 16 линков на коаксиале. В общем, не мой размерчик от слова совсем.
Значит, цифровая. Тем более, что ethernet с wifi у меня точно будет в каждом угле.
Открываю браузер, иду в магазин и немного охреневаю от изобилия камер со всякими аббревиатурами. А цены скачут на три порядка. Что делать, куда бежать?
Первое условие “никаких облаков” сразу отсеивает большую половину камер. Эти камеры потому и дешевы, что сливают китайцам и корейцам все, что можно слить. Новомодным системам надо же на чем-то обучаться? Да и безопасность таких камер хромает на обе ноги – достаточно погуглить и вы обнаружите кучу кредов на любой вкус: хоть напрямую, хоть через “облако”.
А вот следующее условие я не смог внятно сформулировать. Слишком уж много было разноплановой информации. Поэтому я поступил старым проверенным способом: тупо накидал в корзину несколько камер разных производителей и с разной ценой, чтобы лично пощупать и оценить.
Пока камеры ехали, я принялся изучать, чем же их обслуживать. Или, говоря другими словами, DVR, NVR или ip-видеорегистратор. Тут я тоже сразу задрал планку “работает под linux, управление через браузер”. Казалось бы, софта на рынке дофига и больше – бери и пробуй.
Ан, нет. 99% софта – это откровенные поделки, лишь бы было. Особенно этим отличаются отечественные производители. Ни инструкций по настройке, ни поддержки чего-то более-менее распространенного… ничего вообще. Я ставил, смотрел, плевался и удалял. “серверные” версии, которые требуют qtgui? да легко!
Где-то тут приехали и сами камеры, сразу же добавив много интересных аспектов. Например, некоторые камеры сами по себе видеорегистраторы. Можно вставить sd карту, обрисовать зоны для детектора движений и вуаля – все заработает.
Но в итоге самым важным оказалось совершенно другое. Формат, в котором передается видео. MJPEG, H264 и самый моднявый, H265 с плюсиками и буквами на конце. Внезапно для меня это стало могильным камнем для 99,99% видеорегистраторов. Дело в том, что чем моднее формат, тем меньше он требует диска для хранения. В проспектах буржуев я встречал, что H265 S+ требует до 70% меньше места, чем H264.
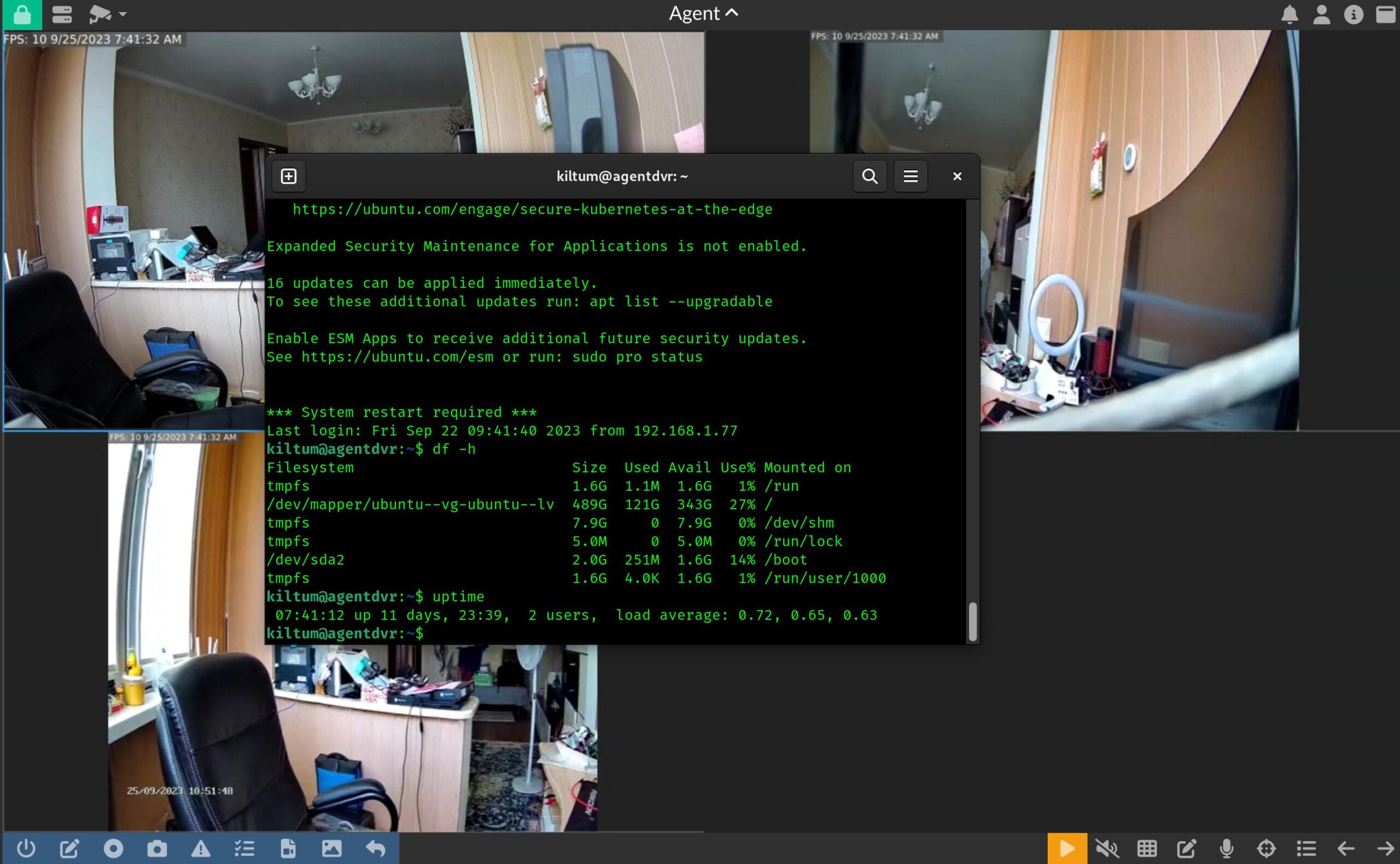
В итоге с банальной задачей “смотри в камеры, если обнаружишь движение, пиши на диск” справился только один видеорегистратор – AgentDVR. Все остальные, включая широко известный ZoneMinder – тупо крешились, жрали проц и память и так далее и тому подобное. Отдавать им такую важную задачу – глупость высшего уровня.
Выше – скриншот с тестовой инсталляции AgentDVR. Три камеры – 4МП, 2МП и 2МП. Пишется по детектору движения. Как видите, за 11 дней сожрало 120 гигов. И процессор совершенно не нагружен. Было бы прелестно, если бы была хоть какая-то интеграция со сторонними системами. Нет, она вроде заявлена, но за помесячную денежку. Не подходит – я готов заплатить за софт, но единоразово.
Увидев подобные цифры потребления, я воспрял духом. Никаких петабайт на глубину в неделю не нужно – хватит и обычных объемов! А их, как вы понимаете, есть у меня!
Следующий шаг – это полностью “аппаратные” решения. Специализированные, заточенные на работу с камерами и только с камерами. Ну и за кучу (или не очень) денежек.
И тут очередная засада. Как выбрать видеорегистратор? Ни одна собака не пишет, сколько камер он может понятнуть. Вместо этого вовсю рекламируют, сколько потоков с каким разрешением он может одновременно отображать. Но мне-то это не надо…
Когда ко мне приехала очередная пачка железок, то тайна оказалась не такой-то уж и тайной. У каждого приличного видеорегистратора есть параметр “максимальный входной поток”. Он измеряется в мегабитах. И чтобы подсчитать, сколько камер потянет регистратор, надо просто принять “1 мегапиксел камеры = 1 мегабит на регистраторе”. И не смотрите, что 4МП камера выдает по сети всего 600-800 килобайт в секунду – это не те потоки, не итшные. В итоге для трех камер на 4, 2 и 2 мегапикселя нужен регистратор, умеющий переваривать поток в 9+ мегабит. Почему не 8? Оставьте небольшой процент на всякие просадки, усушки и утруски.
С дисками вообще все просто: подойдет абсолютно любой. Но если деньги есть, то надо взять именно для систем видеонаблюдения. Во-первых, они все медленные, 5200, а значит холодные и тихие. А во-вторых, в них льется спецпрошивка, которая оптимизирована для постоянной записи в кучу потоков. Мелочь, но по словам бывалых, на нагруженных системах увеличивает срок службы с года до трех практически гарантированно.
Вот мой, купленный на пробу от tiandy. Два диска, 200МБ входного. Усб справа для ориентира в размерах.
Сами регистраторы тоже разные. Самые простые умеют просто писать поток с камеры на диск. Платы таких на али можно найти от 1500 рублей. У регистраторов покруче добавляется возможность писать на внешние диски, в случае каких-то событий отправлять письма, включать что-то внешнее и прочее подобное.
И тут меня настигла первая засада: у “дешевых” регистратов вся аналитика (распознование человек-машина, границы и так далее) ложится исключительно на камеры. Если камера не умеет (или железка не знает про возможности камеры) – то регистратор напишет “ой, и я тоже не могу”. Вот мой, к примеру, не может.
Вторая засада та же, что и с отечественными: документации нет. Вообще. Пара-тройка страничек с общими телодвижениями и все. Поначалу я думал, что это мне так повезло. Но нет, даже у хваленого HikVision та же фигня.
Значит что? Оставляем текущую мешанину работать, набираться опыта и приступаю к тестированию регистраторов под windows. Причем, раз аппетит пришел, с особым упором на аналитику, ибо задача простой записи по движению решена аж двумя способами.
Я как-то привык к заикающемуся и запинающемуся звуку внутри виртуалки. Ну сколько не пробовал разных рецептов, помогали … не очень. А тут внезапно выдался свободный часик и я решил немного погуглить. Оказывается, проблема известная, только не все знают про ее решение.
Скопировал файлик, заменил значения … и вуаля! Звук снова в наличии.