При тестировании всяких штук очень часто получается так, что при удалении неймспейсов они замерзают в Terminating. Могут на 5 минут, могут на сутки. Нашел рецепт
for ns in $(kubectl get ns --field-selector status.phase=Terminating -o jsonpath='{.items[*].metadata.name}')
do
kubectl get ns $ns -ojson | jq '.spec.finalizers = []' | kubectl replace --raw "/api/v1/namespaces/$ns/finalize" -f -
done
for ns in $(kubectl get ns --field-selector status.phase=Terminating -o jsonpath='{.items[*].metadata.name}')
do
kubectl get ns $ns -ojson | jq '.metadata.finalizers = []' | kubectl replace --raw "/api/v1/namespaces/$ns/finalize" -f -
done
Нашел тут https://stackoverflow.com/questions/65667846/namespace-stuck-as-terminating
Давеча столкнулся с непонятным (для меня до сегодня) поведением cgroup. Изначально описание проблемы было очень информативным “сервер тормозит”.
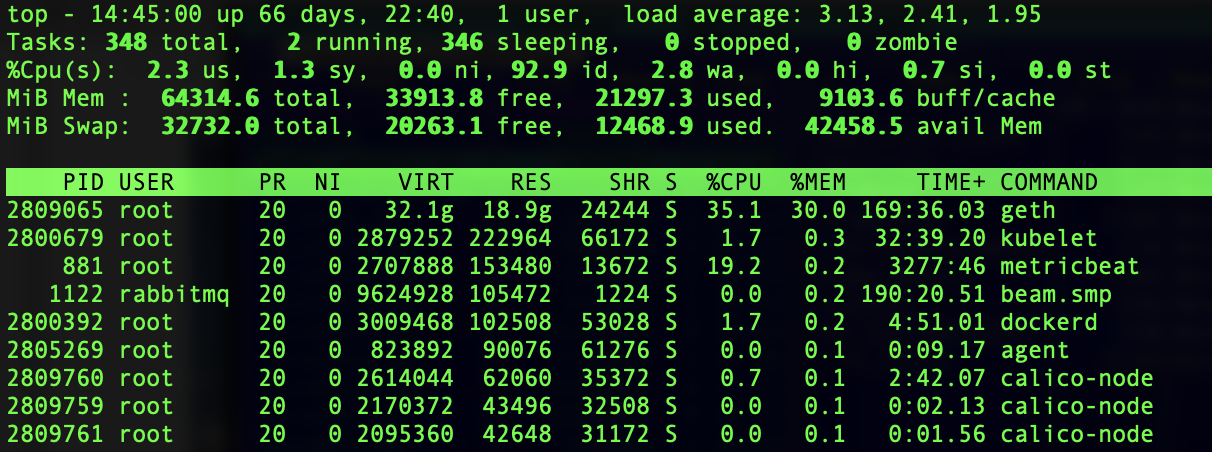
Захожу я на сервер и вижу картину маслом:
Куча свободной памяти, но сервер сидит в свопе и выбираться оттуда категорически не желает. Я последовательно начал перебирать все известные мне лимиты и ограничения: везде норм, хорошо и ничего не вызывает подозрений.
Так как эта нода кубернетеса, то я посмотрел и на ограничения подов в /sys/fs/cgroup/memory/. Тоже все согласно описанному, везде memory.limit_in_bytes соответствуют нужному.
Затем я скопипастил микроскрипт что бы посмотреть, кто занял своп
SUM=0
OVERALL=0
for DIR in `find /proc/ -maxdepth 1 -type d -regex "^/proc/[0-9]+"`
do
PID=`echo $DIR | cut -d / -f 3`
PROGNAME=`ps -p $PID -o comm --no-headers`
for SWAP in `grep VmSwap $DIR/status 2>/dev/null | awk '{ print $2 }'`
do
let SUM=$SUM+$SWAP
done
if (( $SUM > 0 )); then
echo "PID=$PID swapped $SUM KB ($PROGNAME)"
fi
let OVERALL=$OVERALL+$SUM
SUM=0
done
echo "Overall swap used: $OVERALL KB"
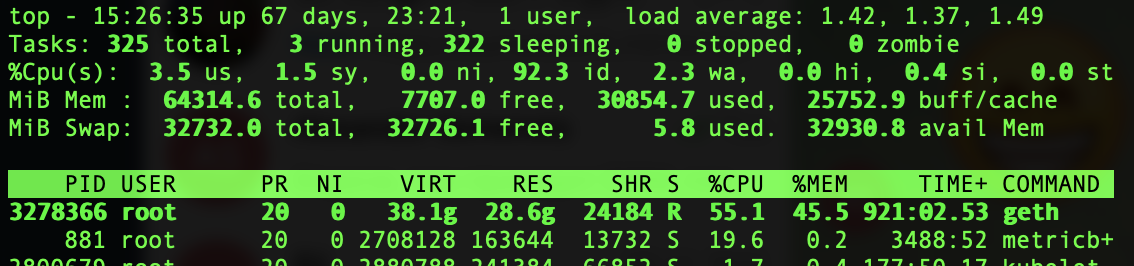
Но скрипт выдал совершенно не совпадающие с системными утилитами значение. Согласно его выводу, своп использовался на 6 гигов. А я вижу на скриншоте выше – 12. Проверил выборочно значения из /proc – совпадают с высчитанными …
Ок, проверю вообще работу подсистему памяти. Набросал быстренько микропрограммку на С, которая раз в секунду сжирала гиг памяти. top честно показал сначала исчерпание free, потом окончание свопа. После пришел OOM и убил программку. Всё правильно, всё так и должно быть.
Долго я ломал голову и пробовал разные варианты. Пока в процессе очередного созерцания top внезапно глаз не зацепился за главного пожирателя памяти. Вернее за его показатель VIRT в 32 гига памяти. Так-то я смотрел на %MEM и RES. В общем, появился резонный вопрос “какого?”
Забрезжила идея, что что-то не так с cgroup. Ок, делаю группу с лимитом памяти в 10 гигов, проверяю, что memory.limit_in_bytes стоят, запускаю снова программку-пожиратель памяти … и вуаля! Через 10 секунд сожралось ровно 10 гигов RAM, и начал жраться своп. Вопрос “какого?” стал более актуальным
Начал гуглить. https://www.kernel.org/doc/Documentation/cgroup-v1/memory.txt говорит скромно
memory.memsw.usage_in_bytes # show current usage for memory+Swap (See 5.5 for details)
memory.limit_in_bytes # set/show limit of memory usage
memory.memsw.limit_in_bytes # set/show limit of memory+Swap usage
Про memsw я специально добавил. Но на этой машине Ubuntu 20.04 с cgroup V2 и параметра с memsw нет. Нахожу дальнейшим гуглежом https://www.kernel.org/doc/html/latest/admin-guide/cgroup-v2.html
The main argument for a combined memory+swap facility in the original cgroup design was that global or parental pressure would always be able to swap all anonymous memory of a child group, regardless of the child’s own (possibly untrusted) configuration. However, untrusted groups can sabotage swapping by other means – such as referencing its anonymous memory in a tight loop – and an admin can not assume full swappability when overcommitting untrusted jobs.
Особенно понравились слова про саботаж. То есть, докер ограничивал использование только RAM, но не SWAP. Теперь, когда проблема стала понятной, стало понятно, что и надо гуглить.
Исходная ситуация: есть сервис, который использует PV, который необходимо увеличить. Примем, что другого (кроме стандартных утилит кубера) доступа к дискам нет от слова совсем.
В моем случае я увеличивал размер /data для prometheus.
Для начала запускаю копирование данных на локальную машину.
Где меняю persistentVolumeReclaimPolicy на Retain. Это необходимо, что бы PV не удалился при удалении/изменении PVC.
Делаю полностью аналогичное для нового PV и удаляю новый же PVC. Теперь у меня есть старый и новый PV. Опять редактирую новый PV, на этот раз убивая секцию claimRef. Это “отцепит” новый PV от несуществующего уже PVC и разрешит его монтировать куда угодно.
Теперь можно заменить volumeName в старом PVC. Ну или тупо грохнуть и создать новый по образцу
Внезапно и совершенно неожиданно для себя обнаружил, что на udemy курсы значительно внятней и понятней, чем на coursera. Мой любимый тест “на кубернетес”, который coursera вместе с Хайтауэром провалила тотально и полностью (там большая часть курса – тотальный бред. С тех пор я уверен, что в Kubernetes Up & Running Хайтауэр только ради политкорректности), тут не вызвал никаких проблем.
В общем, я на udemy набрал курсов, теперь во всю обучаюсь.
Картинка просто для привлечения внимания и как свидетельство, что я там слушаю.