Это черновая версия, финальная опубликована на хабре

Очень часто (да что там часто, практически всегда) микроконтроллеры применяют в условиях, когда необходимо отслеживать сразу несколько параметров. Или наоборот, управлять одновременно несколькими устройствами.
Вот задача для примера: у нас есть 4 выхода, на которых необходимо выводить импульсы разной длительности с разными паузами. Все, что у нас есть – это системный таймер, который считает в миллисекундах.
Усложняем задачу в духе “сам себя замучаю на ардуино”. Таймеры заняты другим, PWM не подходит, ибо не на всех ножках он работает, да и не загонишь его на нужные режимы обычно. Немного подумав, садимся и пишем примерно такой код
// инициализация
int time1on=500; // Время, пока выход 1 должен быть включен
int time1off=250; // Время, пока выход 1 должен быть выключен
unsigned int now=millis();
....
// где-то в цикле
if(millis()<now+time1on)
{
port1=ON;
}
else
{
port1=OFF;
if(millis()>now+time1on+time1off)
{
now=millis();
}
}
И так или примерно так для всех 4 портов. Получается приличная портянка на несколько экранов, но эта портянка работает и работает довольно быстро, что для микроконтроллера важно.
Потом внезапно программист замечает, что при каждом цикле дергается порт, даже если его состояние не меняется. Правит всю портянку. Потом число портов с такими же потребностями увеличивается в два раза. Программист плюет и переписывает все в одну функцию типа PortBlink(int port num).
Почти наступило счастье, но внезапно потребовалось что бы на каком-то порту вместе с управлением “на выход” что-то предварительно считывалось и уже на основе этого считанного управлялся порт. Программист снова матерится и делает еще одну функцию, специально под порт.
Счастье? А вот фигу. Заказчик что-то этакое прицепил и это считанное может легко тормознуть процесс на секунды … Начинается стенания, программисты правят в очередной раз код, окончательно превращая его в нечитаемый треш, менеджеры выкатывают дикие прайсы заказчику за добавление функционала, заказчик матерится и решает больше никогда не связываться со встроенными решениями.
(типа реклама и восхваление) А все почему? Потому что изначально было принято неправильное решение о платформе. Если есть возможность, мы предлагаем навороченную платформу даже для примитивных задач. По опыту стоимость разработки и поддержки потом оказываются гораздо ниже. Вот и сейчас для управления 8мю выходами я возьму STM32F3, который может работать на 72МГц. (шепотом) На самом деле просто у меня под рукой демоплата с ним (смаил). Была еще с L1, но мы ее нечаянно использовали в одном из проектов.
Открываем STM32Cube, выбираем плату, включаем галочку около FreeRTOS и собираем проект как обычно. Нам ничего этакого не надо, поэтому оставляем все по умолчанию.
Что такое FreeRTOS? Это операционная система почти реального времени для микроконтроллеров. То есть все, что вы слышали про операционные системы типа многозадачности, семафоров и прочих мутексов. Почему FreeRTOS? Просто ее поддерживает STM32Cube ;-). Есть куча других подобных систем – та же ChibiOS. По своей сути они все одинаковые, только различаются командами и их форматом. Тут я не собираюсь переписывать гору книг и инструкций по работе с операционными системами, просто пробегусь широкими мазками по наиболее интересным вещам, которые очень сильно пмогают программистам в их нелегкой работе.
Ладно, буду считать что прочитали в интернете и прониклись. Смотрим, что поменялось
Где-то в начале
static void StartThread(void const * argument);
и после всех инициализаций
/* Create Start thread */
osThreadDef(USER_Thread, StartThread, osPriorityNormal, 0, configMINIMAL_STACK_SIZE);
osThreadCreate (osThread(USER_Thread), NULL);
/* Start scheduler */
osKernelStart(NULL, NULL);
И пустая StartThread с одним бесконечным циклом и osDelay(1);
Удивлены? А между тем перед вами практически 90% функционала, которые вы будете использовать. Первые две строки создают поток с нормальными приоритетом, а последняя строка запускает в работу планировщик задач. И все это великолепие укладывается в 6 килобайт флеша.
Но нам надо проверить работу. Меняем osDelay на следующий код
HAL_GPIO_WritePin(GPIOE,GPIO_PIN_8,GPIO_PIN_RESET);
osDelay(500);
HAL_GPIO_WritePin(GPIOE,GPIO_PIN_8,GPIO_PIN_SET);
osDelay(500);
Компилируем и заливаем. Если все сделано правильно, то у нас должен замигать синий светодиодик (на STM32F3Discovery на PE8-PE15 распаяна кучка светодиодов, поэтому если у вас другая плата, то смените код)
А теперь возьмем и растиражируем полученную функцию для каждого светодиода.
static void PE8Thread(void const * argument);
static void PE9Thread(void const * argument);
static void PE10Thread(void const * argument);
static void PE11Thread(void const * argument);
static void PE12Thread(void const * argument);
static void PE13Thread(void const * argument);
static void PE14Thread(void const * argument);
static void PE15Thread(void const * argument);
Добавим поток для каждого светодиода
osThreadDef(PE8_Thread, PE8Thread, osPriorityNormal, 0, configMINIMAL_STACK_SIZE);
osThreadCreate (osThread(PE8_Thread), NULL);
И перенесем туда код для зажигания светодиода
static void PE8Thread(void const * argument)
{
for(;;)
{
HAL_GPIO_WritePin(GPIOE,GPIO_PIN_8,GPIO_PIN_RESET);
osDelay(500);
HAL_GPIO_WritePin(GPIOE,GPIO_PIN_8,GPIO_PIN_SET);
osDelay(500);
}
}
В общем все однотипно.
Компилируем, заливаем … и получаем фигу. Полную. Ни один светодиод не мигает.
Путем страшной отладки методом комментирования выясняем, что 3 потока работают, а 4 – уже нет. В чем проблема? Проблема в выделенной памяти для шедулера и стека.
Смотрим в FreeRTOSConfig.h
#define configMINIMAL_STACK_SIZE ((unsigned short)128)
#define configTOTAL_HEAP_SIZE ((size_t)3000)
3000 байт на все и каждой задаче 128 байт. Плюс еще где-то надо хранить информацию о задаче и прочем полезном. Вот поэтому, если ничего не делать, планировщик при нехватке памяти даже не стартует.
Судя по факам, если включить полную оптимизацию, то сам FreeRTOS возьмет 250 байт. Плюс на каждую задачу по 128 байт для стека, 64 для внутреннего списка и 16 для имени задачи. Считаем: 250+3*(128+64+16)=874. Даже до килобайта не дотягивает. А у нас 3 …
В чем проблема? Поставляемая с STM32Cube версия FreeRTOS слишком старая (7.6.0), что бы заиметь vTaskInfo, поэтому я зашел сбоку:
Перед и после создания потока я поставил следующее (fre – это обычный size_t)
fre=xPortGetFreeHeapSize();
Воткнул брекпоинты и получил следующие цифры: перед созданием задачи было 2376 свободных байт, а после 1768. То есть на одну задачу уходит 608 байт. Повтыкал еще. Получил цифры 2992-2376-1768-1160. Цифра совпадает. Путем простых логических умозаключений понимаем, что те цифры из фака взяты для какого-нибудь дохлого процессора, со включенными оптимизациями и выключенными всякими модулями. Смотрим дальше и понимаем, что старт шедулера отьедает еще примерно 580 байт.
В общем, принимаем для расчетов 610 байт на задачу с минимальным стеком и еще 580 байт для самой ОС. Итого в TOTAL_HEAP_SIZE надо записать 610*9+580=6070. Округлим и отдадим 6100 байт – пусть жирует.
Компилируем, заливаем и наблюдаем, как мигают все светодиоды разом. Пробуем уменьшить стек до 6050 – опять ничего не работает. Значит, мы подсчитали правильно 🙂
Теперь можно побаловаться и позадавать для каждого светодиодика свои промежутки “импульса” и “паузы”. В принципе, если обновить FreeRTOS или поколдовать в коде, то легко дать точность на уровне 0,01мс (по умолчанию 1 тик – 1мс).
Согласитесь, работать с 8ю задачами поодиночке гораздо приятней, чем в одной с 8ю одновременно? В реальности у нас в проектах обычно крутится по 30-40 потоков. Сколько было бы смертей программистов, если всю их обработку запихать в одну функцию я даже подсчитать боюсь 🙂
Следующим шагом нам необходимо разобраться с приоритетами. Как и в реальной жизни, некоторые задачи “равнее” остальных и им необходимо больше ресурсов. Для начала заменим одну мигалку мигалкой же, но сделанной неправильно, когда пауза делается не средствами ОС, а простым циклом.
То есть вместо osDelay() вставляется вот такой вот ужас.
for(int i=0;i<1000000;i++)
{
c++;
}
Число циклов обычно подбирается экспериментально (ибо если таких задержек несколько, то куча головной боли в расчетах обеспечено). Эстеты могут подчитать время выполнения команд.
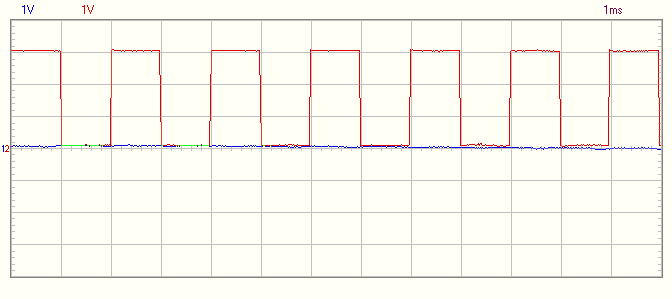
Заменяем, компилируем, запускаем. Светодиодики мигают по прежнему, но как-то вяло. Просмотр осциллографом дает понять, что вместо ровных границ (типа 50мс горим и 50мс не горим), границы стали плавать на 1-2мс (глаз, как ни странно, это замечает). Почему? Потому что FreeRTOS не система реального времени и может позволить себе такие вольности.
А теперь давайте поднимем приоритет этой задаче на один шажок, до osPriorityAboveNormal. Запустим и увидим одиноко мигающий светодиод. Почему?
Потому что планировщик распределяет задачи по приоритетам. Что он видит? Что задача с высоким приоритетом постоянно требует процессор. Что в результате? Остальным задачам времени на работу не остается.
А теперь понизим приоритет на один шаг от нормального, до osPriorityBelowNormal. В результате планировщик, дав поработать нормальным задачам, отдает оставшиеся ресурсы "плохой".
Отсюда можно легко вывести первое правило программиста: если функции нечего делать, то отдай управление планировщику.
В FreeRTOS есть два варианта "подожди"
Первый вариант "просто подожди N тиков". Обычная пауза, без каких либо изысков: сколько сказали подождать, столько и ждем. Это vTaskDelay (osDelay просто синоним). Если посмотреть на время во время выполнения, то будет примерно следующее (примем что полезная задача выполняется 24мс):
... [0ms] - передача управления - работа [24ms] пауза в 100мс [124ms] - передача управления - работа [148ms] пауза в 100мс [248ms] ...
Легко увидеть, что из-за времени, требуемой на работу, передача управления происходит не каждые 100мс, как изначально можно было бы предположить. Для таких случаев есть vTaskDelayUntil. С ней временная линия будет выглядеть вот так
... [0ms] - передача управления - работа [24ms] пауза в 76мс [100ms] - передача управления - работа [124ms] пауза в 76мс [200ms] ...
Как видно, задача получает управление в четко обозначенные временные промежутки, что нам и требовалось. Для проверки точности планировщика в одном из потоков я попросил делать паузы по 1мс. На картинке можете оценить точность работы с 9ю потоками (про StartThread не забываем)

Думаю, для первой части достаточно :)
Как обычно, полный пакет проекта можно взять тут: http://kaloshin.ru/stm32/freertos/stage1.rar