Жил я долго и счастливо с ssh, где приватный ключ хранился в Yubikey и GnuPG (https://blog.kiltum.tech/2025/03/04/yubikey-ssh-final/). Все было хорошо до тех пор, пока мне не потребовалось засунуть приватный ключ в другую систему, которая тупа и вообще ничего другого не принимает как класс.
“Ну фигня вопрос, счас загуглю и быстренько сделаю”. А вот фиг по всей моей физиономии. Все рецепты, что предлагал гугл вместе с нейронками – абсолютно не рабочие. По одной простой причине: они все расчитаны на то, что ключи будут в формате RSA. А у меня-то ed25519. В итоге то у gpg нет такого ключика, то формат не туда, то еще какая фигня на постном масле.
Очень похоже на правду, поэтому командуем разшифровать этот файл
$ echo 'PASSWD AE9CE2AC2E83722BE5F0508C7D131E91CD5FA317' | gpg-connect-agent
S KEYGRIP AE9CE2AC2E83722BE5F0508C7D131E91CD5FA317
S CACHE_NONCE DF9204BEA240BA3CD2986C2E
OK
Оно спросит пароль, потом новый (оставьте пустым) и еще раз “уверены ли мы”. И вот теперь мы его обнаруживаем расшифрованным (я данные заменил на Х)
#!/usr/bin/env python
# /// script
# requires-python = ">=3.13"
# dependencies = [
# "cryptography",
# ]
# ///
import os
import pathlib
import sys
import cryptography.hazmat.primitives.serialization
import cryptography.hazmat.primitives.asymmetric
keygrip = sys.argv[1]
gpg_file = pathlib.Path("~/2/.gnupg/private-keys-v1.d/").expanduser() / f"{keygrip}.key"
with open(gpg_file, "r") as f:
gpg_data = f.read()
# Rather than elegantly parse the S-expression in the .key file, split it on
# the hashes which surround the key material, and pull out the public (q) and
# private (d) parts.
(_, gpg_q, _, gpg_d, _) = gpg_data.split("#")
gpg_d = bytes.fromhex(gpg_d)
d = cryptography.hazmat.primitives.asymmetric.ed25519.Ed25519PrivateKey.from_private_bytes(
gpg_d
)
private_bytes = d.private_bytes(
encoding=cryptography.hazmat.primitives.serialization.Encoding.PEM,
format=cryptography.hazmat.primitives.serialization.PrivateFormat.OpenSSH,
encryption_algorithm=cryptography.hazmat.primitives.serialization.NoEncryption(),
)
os.umask(0o0077)
ssh_key_file = pathlib.Path("~/.ssh").expanduser() / f"id_ed25519.{keygrip}"
with open(ssh_key_file, "w") as f:
f.write(private_bytes.decode())
print(f"SSH key written to {ssh_key_file}")
И пущаем его (как ставить модули в питон, если у вас их нет – в гугл)
python3 t.py AE9CE2AC2E83722BE5F0508C7D131E91CD5FA317
SSH key written to /Users/vvkaloshin/.ssh/id_ed25519.AE9CE2AC2E83722BE5F0508C7D131E91CD5FA317
Успешный успех! Я проверил: ключик действительно тот и ssh -i проглатывает его совершенно без каких-либо стеснений. Теперь осталось засунуть его куда надо и подчистить за собой ошметки и незашифрованные ключи.
В общем-то, провайдерский роутер RX-33412 вполне себе железка. Подключили и он работал совершенно без каких-либо претензий. Правда, я сразу на нем отключил WiFi, ибо по отзывам, оно обожает перегреваться и тащит за собой все остальное. А оно мне надо? Тем более у меня есть нормальная WiFi сеть с мешами и прочим, чего этот роутер не умеет.
В чем была боль? В двойном NAT. Чтобы пробросить порты, надо было сначала вручную на первом роутере прописать, потом на втором. Ну и лишние миллисекунды потерь на роутинге тоже резали ножом мою нежную ИТ душу. Итого было принято решение перестать выкапывать стюардессу и сделать по-нормальному.
А как по-нормальному? Вместо роутера нужен был бридж. Иначе говоря, провайдерский роутер должен был превратиться в тупой транслятор “оптика – ethernet”. И, в принципе, он это умеет: достаточно просто в настройках повернуть крыжик. Но (опять это но!) в куче сообщений на форуме 4pda были жалобы, что если что, то тупая автоматика ростелекома через TR-069 сбрасывает эти настройки на “умолчательные”, сиречь роутер вместо бриджа. Решения, конечно, есть. Первое это обратиться в саппорт и попросить их у себя в настройках сменить. Второе: купить ONT коробочку и сделать все самим. А провайдерский оставить в качестве резерва. Я пошел по второму варианту.
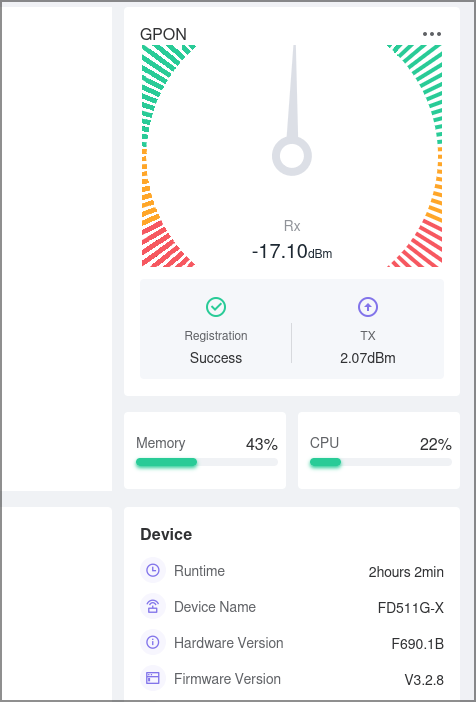
Купил Оптический абонентский терминал xPON ONT/ONU 1GE FD511G-XA MINI 1 порт GPON/EPON, 1490/1310 нм, 20 км, SC/APC. Пока он ехал, скопировал все относящееся к GPON, что нашел. Почитал 4pda, нашел метод взлома, выдающий пароль от superadmin. Получил, походил посмотрел. В общем-то ничего полезного (кроме настроек TR-069) не нашел. Но все равно записал в блокнотик.
Приехала онушка. Воткнул кабель, прописал 192.168.101.10/24, зашел с кредами adminisp/adminisp и принялся смотреть. Но опять смотреть оказалось нечего. В WAN создаем бридж с VLAN 10, в GPON прописываем GPON_SN, спертый с провайдерского роутера, остальные поля удаляем. И сохраняем, вернее пытаемся сохранить. Оказывается, 3я версия прошивки не дает полю SN Password быть пустым. Еще немного погуглил и забил туда десять ноликов. Сохранил.
Подключил оптику, включил питание и …
Дальше уже совсем просто: в моем роутере прописал PPPoE, вбил логин и пароль и оно заработало.
Последний шаг нужен для тех, у кого UniFi Cloud Gateway Ultra. UCG не умеет делать бридж и роутинг на одном порту. В итоге после подключения я потерял доступ к админке ONT. Мелочь? Мелочь, но не приятная. Как теперь смотреть красивые циферки-то? Благодаря тому, что внутри у UCG обычный линукс, идем в консоль и запускаем пару комманд
ip addr add dev eth4 local 192.168.101.2/24
iptables -t nat -A POSTROUTING -o eth4 -d 192.168.101.0/24 -j SNAT --to 192.168.101.2
Теперь все снова доступно. Как говорится, попробуйте повторить это на кинетике … Минус только один: после перезагрузки это надо будет повторить 🙂
Я давний фанат keenetic’ов. Ну как минимум был до последних событий. Вся их линейка абсолютно соответствовала моему главному принципу “не трахай мне мозг”. Купил, достал, подключил, соеденил, забил логины-пароли и оно работает себе. Так продолжалось… ну лет много в общем.
Но все изменилось с последней реорганизации сети у меня дома. Я наконец-то дорос до отдельной комнаты, где поселились сервера в стойке, нормальные коммутаторы и прочие патч-панели. Поглядев на получившееся великолепие, я начал пересаживать кинетик на новое место жительства.
И тут начались странности и жалобы. Если проводная часть (читай стационарные компы и виртуалки) работали отлично, то WiFi колбасило, причем очень странно. Например, у меня появился “заколдованный” угол, где включаешь любой кинетик и через некоторое время у него пропадает диапазон 5ГГц. И время колеблется от “сразу” до “ну где-то через полчаса”. Ок, пока разбираемся с 5ГГц, можно ведь пожить и на 2х, верно ведь? Нет, не верно. Не знаю, что там и где не стыкуется у кинетика с маком, но его иногда начало перепинывать от точки к точке. И ладно бы просто перепинывало, но иногда его забрасывало на самую удаленную точку, где сигнал иногда терялся. А потеря сигнала – потеря коннекта – сброс всех впн и прочих соединений. Быстрая припарка в виде близкой точки доступа, включенной в меш, помогла, но это же костыль…
В общем, я дошел до ручки и пошел писать в техподдержку кинетика. Впервые за много лет я не смог побороть сетевую часть. Надо отдать должное, там довольно быстро вьехали в суть и практически на первом ответе выдали ответ. Вот он дословно.
Для корректной работы Wi-Fi системы, от стороннего оборудования в сети требуется пропуск STP и LLDP.
В Wi-Fi системе протокол STP используется для управления связями между ретрансляторами. LLDP – для определения контролера в сети. Если промежуточное оборудование в сети вмешивается в работу STP/LLDP, либо не пропускает пакеты BPDU протокола STP – работа Wi-Fi системы будет нарушена. Симптомы при этом: петли, сетевой шторм, в случае если ретрансляторы видят транспортную сеть контроллера и подключаются к ней. А если ретрансляторы транспортную сеть не видят, то на них остается включенным беспроводной клиент, который вхолостую сканирует эфир, вызывая потери на собственной точке доступа. Могут возникать разные негативные эффекты.
Если все ретрансляторы подключены кабелями, можно отключить на Keenetic-контроллере “Беспроводную транспортную сеть” в настройках Wi-Fi системы, это, как минимум, уберет возможную петлю. Но, если проблема в STP, это не решает ее полностью, лишь отчасти маскирует ее.
Если имеется оборудование с поддержкой STP, его нужно настраивать: можно попробовать отключить на нем STP/RSTP/MSTP, но тогда есть вероятность, что будут отбрасываться BPDU-пакеты, что тоже не годится. Может помочь включение опции BPDU Flooding, если такая есть.
Нужно настроить таким образом, чтобы у всех коммутаторов был меньше приоритет в топологии STP и они не занимали место Keenetic-контроллера. Корнем дерева STP должен быть контроллер. По умолчанию и Keenetic, и коммутаторы имеют значение STP Bridge Priority 32768 DEC или 8000 HEX. Чем ниже значение, тем выше приоритет узла. Нужно либо повысить значение на коммутаторах, либо понизить на Keenetic.
Мне потом его еще раз прислали слово-в-слово, из чего я сделал вывод, что эта проблема шаблонная, как и рецепты по ее исправлению. Ну если с STP есть вариант попробовать, то с LLDP полный швах. Ни один свитч попросту не пропустит LLDP пакеты через себя, потому что это нарушает стандарты.
Если пропустить дальнейшую переписку и перейти сразу к сути, то выявляются два пункта, которые стали причиной моего отказа от кинетиков.
Пункт 1: Между кинетиками должны быть только хабы. Сейчас они маскируются под “неуправляемые свичи”. Или сами кинетики. Как выяснилось, их сетевая часть плюет на стандарты в этом месте.
Пункт 2: Пока точка доступа не видит контроллер по LLDP, она НЕ ПЕРЕСТАЕТ сканировать сеть в поисках транспортной. Пофиг на то, что контроллер видит точку доступа и рулит ей. Пофиг на пинги и прочее. Нет lldp? Нет и 5ГГц. Это и стало причиной глюков по 5ГГц. Точка доступа поднимает SSID, набирает клиентов, гонит трафик… Потом просыпается что-то внутри “ой, а где контроллер” и она начинает сканировать эфир, посылая клиентов нахер. Не найдя, она поднимает все назад и процедура повторяется. А клиенты шарахаются с точки на точку и с канала на канал.
Быстро собрав отдельную сеть для кинетиков и пригасив негатив (читай: у мака wifi стал отваливаться не каждые 10-15 минут, а пару раз за день), я принялся искать варианты. Первыми попались на глаза и ушли консьюмерские дивайсы. Asus, TP-Link и прочие Xiaomi. Почитав обзоры и погуглив разное, я решил, что повторения болей мне не надо. Где-то нет меша через провод, где-то управлялка только через мобильник, где-то еще какая закавыка…
Ладно, пойдем к корпоратам. Так сказать, чем мой дом не SOHO? Первым попал под микроскоп microtik. Первым минусом стало то, что WiFi у микротиков традиционно слабый. Но это мелочи, можно просто побольше точек напихать, благо у меня чердак неэксплуатируемый. Но вот winbox и прочее стали барьером. Я как-то привык к принципу “рулим отовсюду и без особых заморочек”.
И тут на сцену вышел Ubiquiti. У них есть решения под любые (хорошо, кратно превышающие мои потребности) задачи. Ну и плюс множество восторженных отзывов, что это работает. Не проблема, беру заказываю одну точку доступа на пробу.
Пока она едет, ставлю в виртуалку UniFi Network, единственная задача которой рулить всей сетевой частью дивайсов компании. Есть еще всякие UniFi Access и NVR, но мне не нужны ни замки на двери (читай СКУД), ни запись с камер.
Наконец приехала точка доступа. Первые впечатления: полный восторг! Шаблон для дырочек в комплекте, причем сразу с уровнем. Крепления на стену и на фальшпотолок. А если нужно что-то более экзотическое, то велкам в магазин: там есть хоть на трубы, хоть на черта лысого. Пошел в закрома, нашел уголок и тупо прикрепил к стропилам крыши.
Воткнул в РОЕ коммутатор, раздал VLAN… Пошел в UniFi Network, захватил точку и… Всё. Реально все. Она заработала, показала всё, что надо и вообще как будто тут и была. “Подозрительно”, решил я и принялся ее гонять. Диапазоны, каналы, устойчивость к температурам (на улице была жара +40 в тени, под крышей было до +65) и прочее. Да, куча функционала в network не работало, ибо нужны были другие железки от unifi, но именно к точке доступа претензий не возникло ни одной. Даже мак любезно перешел на нее и был совершенно удовлетворен сетевой частью.
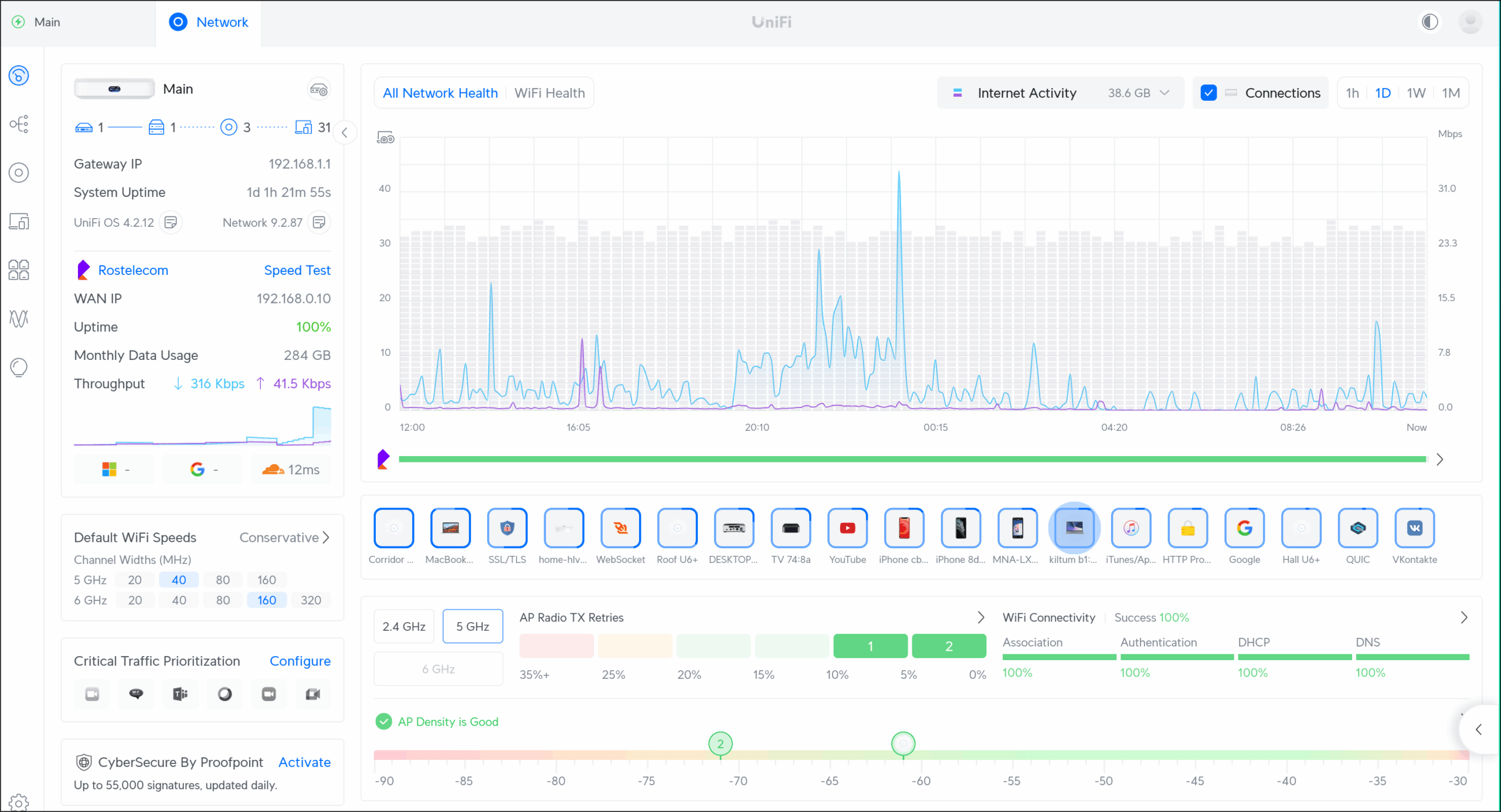
Прошла неделя. Без замечаний. Я заказал UniFi Cloud Gateway (читай: роутер), сверху USW Lite 8 POE (читай коммутатор с РОЕ) и еще три точки доступа. Пока железо ехало, читал гайды и смотрел видосики. На youtube реально куча видео, рассказывающих про все аспекты: начиная от “инсталяция с нуля для нубов” и заканчивая “у меня есть ранчо, чего-то вайфай на горе за 200м от дома плохо ловится”.
Приехало железо. Быстренько раскидал как попало, воткнул куда придется и принялся играться. И оно опять-таки подозрительно все заработало буквально с первой попытки. Да, проблемы возникли.
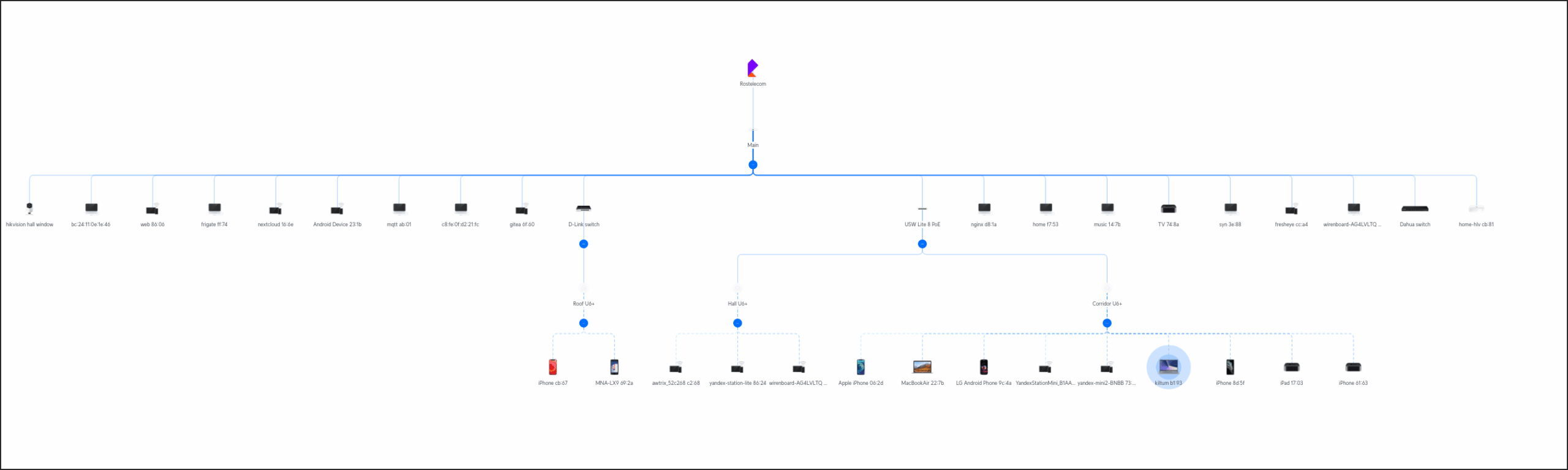
Ну как проблемы. Так, фичи. Например, встроенный показометр топологии почему-то очень вольно обращается с “чужими” свичами. Если поглядеть на картинку сверху, то выглядит, как куча всего подключено напрямую в Main. В реальности они все подключены через свои свитчи. Но это мелочи. В реальности все работает без каких-либо “пропусков LLDP и понижения приоритета STP”.
Наигравшись, через неделю я рано утром выключил все кинетики и переименовал WiFi сеть. И затаился в ожидании “ну чего оно опять не работает”. А фигу. Мне уже стыдно немного за повторения, но оно заработало так, как и ожидалось. Моя лакмусовая бумажка качества сети в виде мака вообще не подавала никаких признаков кислотности в округе. Я даже взял смелость походить между точек доступа во время видеоконференции. Раньше это приводило к секундным паузам, сейчас нет.
Прошла еще одна неделя. Проблем нет. Все работает, все показывается. Все мои 38 устройств не высказывают никаких проблем.
Следующим шагом станет постепенное избавление от “соплей”, которые я навешал в серверной при игрищах и переезде. В сторону: патч-панель это хорошо!
Но это дела дней грядущих. Теперь краткое резюме о том, в чем же keenetic проигрывает unifi. В том порядке, что пришло в голову.
Все (вообще все) дивайсы от убика умеют в vlan и являются управляемыми. Причем управляемыми из одной точки. При числе дивайсов более одного это дает резкий буст в контроле над сетью. У кинетика надо бегать по каждому отдельно, причем часто без права на ошибку. Иначе сброс и начинай все заново.
Все (опять вообще все) конечные дивайсы от убика умеют в РОЕ. Или раздавать или питаться от него. У кинетика это умеет только voyager (и вроде кто-то еще). Отсутствие необходимости в розетке рядом (или приобретать отдельный РОЕ сплиттер) очень и очень выручает.
Управление сетями WiFi вообще не конек кинетика. У убика можно задать, какая сеть на какой точке будет светиться, а какая нет. У кинетика только все разом и только все вместе.
Управляемость сетью у кинетика тоже на уровне плинтуса. Чтобы развести разные сети по разным VLAN, дать доступ одним и запретить другим, отправить трафик не на маршрут по умолчанию, а куда-то еще – надо трахаться. Реально проще всех оставить в одной сети и не мучаться. У убика это делается парой кликов в админке.
Динамические протоколы маршрутизации. У убика все есть. И OSPF и BGP. У кинетика только RIP и тот в зачаточном состоянии. А это значит, что сделать обход мракобесия РКН на убике на порядок проще и надежнее. И я сделал и оно реально проще.
Убик внутри это обычный линукс. Можно зайти по ssh и посмотреть, как оно все там внутри жужжит. Policy Engine? Это iptables с кучей правил. BGP? Это обычный FRR. Команда ip полностью функциональна и с ней можно сотворить внутри системы что угодно. Даже на точке доступа все это есть и работает. У кинетика же внутри какой-то кастрированный шелл, к которому нет документации. Ну нельзя же считать докой гуляющий по сети pdf от старой гиги.
Кинетик угрюмо курит в углу после вопросов по техническим возможностям. Wifi7? Они только-только WiFi6 освоили. 10Гб порты? Вы чего? У нас 2,5Гб только начали появляться. SFP? Вот вам гигабит, его всем хватает! Уличные точки доступа? Ну под крышей поставьте, норм же!
И наконец то, что импортные называют observability. Посмотреть, где и что происходит в сети, кинетик попросту не умеет.
Может показаться, что я хаю кинетик, но это не так. Вообще так (смаил), но возможно я просто перерос его возможности и наши курсы разошлись…
Стоял у меня Plex на synology, раздавал видосики и никак к себе внимание не привлекал. Однако после очередной переделки сети я обнаружил, что все клиенты стали ругаться на недоступность сервера. Зашел в админку, там пишут, что проблемы с сервером.
Ок, потыкал сюда, потыкал туда… Нет, не работает у тебя plex и все тут. Ок, пошел скачал с сайта последнюю версию, обновил. Ничего. Удалил вообще все, поставил и вуаля: You do not have permission to access this server. Пошел гуглить. Везде идиотские советы типа поставь DNS в 1.1.1.1 и 8.8.8.8 и все заработает.
Наконец в какой-то инструкции прочитал, что надо нажать кнопочку claim в админке. Но меня в админку не пускает! Читаю дальше. Везде в инструкции советы типа “найдите в трее иконку сервера и нажмите”. Но у меня нет трея, у меня на насе все!
Решил посмотреть, куда эта страничка лезет. Включил Web Developers tools и обнаружил, что скрипт довольно активно ломится на 127.0.0.1:32400. Ну-ка.. (тут пропущено немного мата и поисков, что же этой штуке надо). Итак, инструкция
Включаем в настройках Synology ssh сервер
Разблокируем пользователя admin (вы же его заблокировали, сразу как настроили, да?). Другие пользователи не подойдут, там хардкод.
ssh -L 32400:127.0.0.1:32400 admin@192.168.90.91 , где 192.168.90.91 адрес сервера
Ну и в браузере вводите http://127.0.0.1:32400 (Не localhost, plex тупой слишком).
Вуаля. Теперь вам открылась админка plex, где есть эта кнопочка claim.
Суть простая: у меня есть сеть с Н выходов наружу. И очень надо, чтобы весь трафик на gmail шел через определенный узел. Казалось бы, фигня вопрос! Берем AS gmail и зароучиваем куда надо. Но фиг-то там. Нет отдельной AS для почты. Там у них все в куче: и почта и ютюб и прочее.
Ок, давай 25й порт завернем … Но опять же, весь почтовый трафик не нужен! Остается только по адресам. Но и тут засада: они меняются. Не часто, но регулярно! Ок, пара минут (ладно, полчаса) и готов такой однострочник.
alias gmail="echo \"conf t\"; for i in {alt1.gmail-smtp-in.l.google.com.,gmail-smtp-in.l.google.com.,alt2.gmail-smtp-in.l.google.com.,alt4.gmail-smtp-in.l.google.com.,alt3.gmail-smtp-in.l.google.com.}; do host \$i 127.0.0.1 | grep has\ address | awk '{ print \"ip route \" \$4 \"/32 37.9.13.1\"; }' ; done; echo \"exit\"; echo \"write\"; echo \"exit\""
На момент написания результат будет такой
conf t
ip route 108.177.125.27/32 37.9.13.1
ip route 64.233.161.26/32 37.9.13.1
ip route 192.178.163.27/32 37.9.13.1
ip route 173.194.208.27/32 37.9.13.1
ip route 142.250.101.27/32 37.9.13.1
exit
write
exit
В результате все текущие почтовые адреса гмыла пойдут через 37.9.13.1 – это адрес роутера в селектеле, через который подключен мой сервер. Как этот вывод скормить FRR автоматично предлагаю решить самостоятельно 🙂
Скажу честно, первый раз такое. Ситуация простая до безобразия: добавляю значения в /etc/sysctl.conf, ребучу и нифига. Заходишь в консоль, sysctl -p – все нормально.
Рано или поздно, но вам понадобится отобразить в логе CI/CD какую-то замаскированную переменную. Причин может быть множество и все они тут не интересны.
Обычно это решается просто методом “на коленке”:
echo ${SSH_USER} | base64
В ответ получаем строку типа Z2l0bGFiLXVzZXIK, копируем ее к себе и пропускаем через base64 -D
Но в 99% нам просто надо убедиться, что значение переменной верное и пойти дальше. Немного погуглив, я сообразил решение:
- echo ${SSH_USER::1}${SSH_USER:1}
На первый взгляд, это не должно сработать: выводим сначала первый символ, потом все, начиная со второго. Гитлаб достаточно умный (или тупой?), чтобы не разбираясь, найти и замаскировать в потоке. Однако пруф вот:
Где обман бедного гитлаба? А шутка ровно посредине. Если смотреть на код в текстовом редакторе, то увидим вот это:
Между частями вставлен специальный unicode символ, который просто пустое место. В итоге “для глаз” всё хорошо, а гитлаб не распознает такую последовательность как требующую маскирования. Задача выполнена!
Где взять такой символ? Самое простое сходить на https://emptycharacter.com/ и выбрать любой понравившийся вариант.
Потребовалось мне тут подменять “на ходу” ответы DNS. Это то самое, чем балуются провайдеры, когда на запросы типа facebook.com отдают 127.0.0.1. Только у меня ситуация чуть проще: и DNS мой и ответы мне нужны тоже … свои.
Конечно, самое простое решение – это подправить /etc/hosts. Но у меня машин много, бегать по каждой… Следующим – заиспользовать zone views. Но у меня зоны раскиданы и фиг его знает, откуда я приду. Немного погуглил и нашел другой вариант. В общем, иду на машинку, где работает named. Создаю файлик зоны. Он совершенно стандартный, за исключением записей.
# cat db.override
$TTL 60
@ IN SOA localhost. root.localhost. (
2015112501 ; serial
1h ; refresh
30m ; retry
1w ; expiry
30m) ; minimum
IN NS localhost.
localhost A 127.0.0.1
hostname.ru CNAME hrentam.zone.ru.
Следом прописываю этот файлик как мастер
zone "override" {
type master;
file "/etc/bind/db.override";
};
И добавляю в опции одну команду
options {
.....
response-policy { zone "override"; };
};
И после перезагрузки named мне начал отвечать тем, что описано в этой зоне. А на остальные запросы – как обычно.
На всякий: в общем-то описанное ранее все работает и даже не вызывает раздражения, но только если ваша работа не связана с регулярными походами по многим ssh серверам. В реальности регулярное ожидание “прикоснитесь к токену” начинает раздражать уже на втором десятке коннектов. А если запустить какой-нибудь ансибл плейбук, так сидишь и настукиваешь по токену, пока плейбук пройдет по серверам. А потом, где-то на середине, опять начинаешь, ибо сессия протухла. В общем, бесит неимоверно.
После гуглежа выяснилось, что у юбиков для fido2 нет опции “не требовать прикосновения Н времени”. Для gpg есть, а для fido – нет. Боль и печаль. Поэтому самый простой способ купировать это поведение – это использовать controlpath в ssh.
Для ssh это лечится добавлением в .ssh/config следующих строк:
ControlMaster auto
ControlPath ~/.ssh/master-%r@%h:%p.socket
ControlPersist 120m
Теперь, стоит вам зайти на любой хост, как любой последующий вход в течении двух часов будет происходить по уже установленной сессии. Никаких касаний и прочего не будет. Для ансибла делаем аналогично:
Теперь что ssh, что ansible будут использовать одни и те же пути, что приводит к повышению производительности. Но боль “коснись 100500 раз” просто загоняется вглубь. Что при первом запуске, что при последующих – все тоже самое. Опять гуглю. Выходит, что мимо gpg хоть так, хоть так не пройти. Ладно, у меня есть gpg!
В принципе, для ssh можно добавить только последний ключ, для auth. Но я решил танцевать по-максимуму. Так, если верить докам, то сейчас у меня уже должена появиться возможность проэкспортить ssh ключ
Вот на тебе по всей морде, а не ssh ключ! Обидно, гуглю дальше. Оказывается, gpg-agent слишком секурный и просто так никому ничего не покажет. Ему надо конкретно указать, какой ключ нужен. Для этого смотрим ид ключей и добавляем в спец-файлик
Итого, оно работает. Но где тут yubikey? А с ним оказалось еще проще. Надо просто перенести ключик из внутренней базы gpg в токен.
ВНИМАНИЕ! Сделайте бекап каталога .gnupg! Он понадобится для второго токена
Для начала выбираем ключ
gpg --edit-key kiltum@kiltum.tech
gpg> key 1
sec rsa4096/D9C4611813E9F51E
created: 2017-09-11 expires: never usage: SC
trust: ultimate validity: ultimate
ssb* rsa4096/B2698444DC05C50F
created: 2017-09-11 expires: never usage: E
ssb ed25519/406890D12CB9E70B
created: 2025-03-04 expires: never usage: S
ssb cv25519/973D20344A973490
created: 2025-03-04 expires: never usage: E
ssb ed25519/24C65C290629B65F
created: 2025-03-04 expires: never usage: A
[ultimate] (1). Viacheslav Kaloshin <kiltum@kiltum.tech>
gpg> key 4
sec rsa4096/D9C4611813E9F51E
created: 2017-09-11 expires: never usage: SC
trust: ultimate validity: ultimate
ssb* rsa4096/B2698444DC05C50F
created: 2017-09-11 expires: never usage: E
ssb ed25519/406890D12CB9E70B
created: 2025-03-04 expires: never usage: S
ssb cv25519/973D20344A973490
created: 2025-03-04 expires: never usage: E
ssb* ed25519/24C65C290629B65F
created: 2025-03-04 expires: never usage: A
[ultimate] (1). Viacheslav Kaloshin <kiltum@kiltum.tech>
gpg> key 1
sec rsa4096/D9C4611813E9F51E
created: 2017-09-11 expires: never usage: SC
trust: ultimate validity: ultimate
ssb rsa4096/B2698444DC05C50F
created: 2017-09-11 expires: never usage: E
ssb ed25519/406890D12CB9E70B
created: 2025-03-04 expires: never usage: S
ssb cv25519/973D20344A973490
created: 2025-03-04 expires: never usage: E
ssb* ed25519/24C65C290629B65F
created: 2025-03-04 expires: never usage: A
[ultimate] (1). Viacheslav Kaloshin <kiltum@kiltum.tech>
Обратите внимание на звездочку около ssb – команда key триггерит выбор ключа, а не отменяет последний выбор! И наконец, записываю ключ в yubi
gpg> keytocard
Please select where to store the key:
(3) Authentication key
Your selection? 3
sec rsa4096/D9C4611813E9F51E
created: 2017-09-11 expires: never usage: SC
trust: ultimate validity: ultimate
ssb rsa4096/B2698444DC05C50F
created: 2017-09-11 expires: never usage: E
ssb ed25519/406890D12CB9E70B
created: 2025-03-04 expires: never usage: S
ssb cv25519/973D20344A973490
created: 2025-03-04 expires: never usage: E
ssb* ed25519/24C65C290629B65F
created: 2025-03-04 expires: never usage: A
[ultimate] (1). Viacheslav Kaloshin <kiltum@kiltum.tech>
Note: the local copy of the secret key will only be deleted with "save".
gpg> save
Вроде ничего не произошло страшного, кроме запроса admin кода, верно? Проверяю
Теперь у ключика, который в yubi, появился символ >. Дескать, он во внешней штуке. Так и должно быть. Но у меня есть второй yubi, в него бы тоже этот ключик засунуть… Как быть? А очень просто: убиваем gpg-agent, восстанавливаем бекап .gnupg, вставляем второй ключ и повторяем операцию с записью ключа. Один-в-один, без всяких изменений.
Выше я, абсолютно ничего не делая, просто поменял токен. gpg-agent опять оказался достаточно разумным, чтобы разрулить эту ситуацию. Теперь у меня есть аж два варианта работы с этим ключем: либо с помощью юбиков, либо восстановить .gnupg из бекапа и забить на юбики. Ключ не изменится! А что самое главное, ключ защищен аж в двух местах: пароль на gpg и пин на юбике. Оба хоть и кешируются (тут удобство для меня), но при перезагрузке/смене ключа спрашиваются (тут радуется внутренний безопасник).
Что необходимо сделать следующим? Во-первых, положить бекап .gnupg в сухое место. Во-вторых, пройтись по всяким серверам и сервисам и добавить новый ssh ключ. И наконец, самое больное: пройтись по всяким серверам и сервисам и заменить публичный pgp ключ. Причина простая и прозаическая: мы добавили новых ключей и всякие git (вы же пользуете подпись в git?) стали автоматом использовать свежее и более защищенное. Пруф:
$ git log --show-signature -1
commit 37ad3b5134621b1df18644b10884b8d17f2879f9 (HEAD -> main, origin/main, origin/HEAD)
gpg: Signature made Tue Mar 4 14:12:19 2025 MSK
gpg: using EDDSA key 12D3317E74826BD633976A76406890D12CB9E70B
gpg: Good signature from "Viacheslav Kaloshin <kiltum@kiltum.tech>" [ultimate]
Вообще зря я вас пугал болью (смаил). Это делается просто:
$ gpg --armor --export
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQINBFm2d2MBEACy9YyMqPeEZEIgndjhyYOOz61WXBZtyrOaeNXlfRy2HjZZ9os2
....
=KxVu
-----END PGP PUBLIC KEY BLOCK-----
И вот этот вот текст вы суете во всем места, где просят GPG public key.
Где были проблемы? На моем пути была только одна: если у вас в gpg стоит pinentry не графический (читай: просто pinentry или pinentry-ncurses), то при попытке добавления другого, старого и проверенного ключа я получал облом.
$ ssh-add .ssh/backup/id_ed25519
Enter passphrase for .ssh/backup/id_ed25519:
Could not add identity ".ssh/backup/id_ed25519": agent refused operation
Лечится это странной командой
$ echo UPDATESTARTUPTTY | gpg-connect-agent
OK
$ ssh-add .ssh/backup/id_ed25519
Enter passphrase for .ssh/backup/id_ed25519:
Identity added: .ssh/backup/id_ed25519 (kiltum@kiltum.tech)
На всякий: удаляются такие ключи из базы gpg тоже не сложно:
$ gpg-connect-agent 'keyinfo --ssh-list' /bye
S KEYINFO AE9CE2AC2E83722BE5F0508C7D131E91CD5FA317 D - - - P - - S
S KEYINFO 716AA423769B73317BBA874ECFD11765948B5EFD D - - - P - - S
OK
$ gpg-connect-agent "delete_key --force 716AA423769B73317BBA874ECFD11765948B5EFD" /bye
OK
В прошлой части я писал про resident ключи. И вроде все работало. А теперь решил попробовать поработать с non-resident. И тут же столкнулся с тем, что хоть ssh-add и работал, но заходить на сервера не получалось. Если запустить ssh -v, то можно было увидеть строчки from agent: agent refused operation
Немного нагуглив, я нашел рецепт: дескать, ssh-agent нужно подтвердить, а ему не у кого. И дескать, лечится установкой ssh-askpass и правки скрипта, который пускает ssh-agent. Ок, правлю вот так:
Все остальное оставляю прежним. Грохаю все и пытаюсь зайти
...
debug1: Will attempt key: /Users/xxxxxx/.ssh/id_ed25519
debug1: Will attempt key: /Users/xxxxxx/.ssh/id_ed25519_sk
debug1: Will attempt key: /Users/xxxxxx/.ssh/id_xmss
debug1: Offering public key: xxxxxx@yyyyy.ru ED25519-SK SHA256:4GX39PbvB7LoXoBzPrxABAt5xC+x05y6WNtgW3qAN+A authenticator agent
debug1: Server accepts key: xxxxxx@yyyyy.ru ED25519-SK SHA256:4GX39PbvB7LoXoBzPrxABAt5xC+x05y6WNtgW3qAN+A authenticator agent
sign_and_send_pubkey: signing failed for ED25519-SK "xxxxxx@yyyyy.ru" from agent: agent refused operation
debug1: Offering public key: xxxxxx@yyyyy.ru ED25519-SK SHA256:W/dXsAitpJKpPcYNf2zB+ucsG+zx50R0hSzIQ2Lwl74 authenticator agent
debug1: Server accepts key: xxxxxx@yyyyy.ru ED25519-SK SHA256:W/dXsAitpJKpPcYNf2zB+ucsG+zx50R0hSzIQ2Lwl74 authenticator agent
debug1: Enabling compression at level 6.
Authenticated to 10.34.178.1 ([10.34.178.1]:22) using "publickey".
debug1: setting up multiplex master socket
...
В логах видно, что у меня два ключа. Первый я вынул и спрятал. А вот второй – на месте. Вот где я добавил пустую строчку – там он стал ждать прикосновения к ключу. Никаких запросов или там окошек всплывающих не появилось. Нафига нужен ssh-askpass? Не знаю. Я даже попробовал перезагрузиться и ключ вставить-вынуть – ничего не поменялось…
Ситуация совершенно стандартная: есть что-то из proxmox, vmware, openstack и нам изредка требуется создавать в нем машинки. Можно пойти классическим путем: закачиваем исошку, создаем виртуалку с этой исошкой и ставим туда все, что нужно. Для ускорения можно добавить cloud-init, всякие конфиги для анаконд и прочее. Ну и потом все это полирнуть ансиблом и паппетом по вкусу. Есть хипстерский вариант: затащить какой-нить терраформ и клауд образа и им штамповать машинки. Больно, долго и муторно, как и все в IaaC.
А можно совместить приятное с полезным. Сделать виртуалку, напихать в нее всё, что надо и как надо, а потом преобразовать ее в темплейт. И уже потом из этого темплейта штамповать виртуалки в любом количестве. По скорости разворота этот способ уделывает все остальные на порядок.
Но тут есть маленькая проблемка: если сделать все прямо в лоб, то все новые машинки будут иметь одинаковые ссш ключи и будут получать один и тот же ip адрес. Итак, рецепт ниже.
Шаг первый: подготавливаем виртуалку как надо вам.
Долго ли, коротко, но в руках у меня снова оказался yubikey. Да, вот эта вот штука, которая устами манагеров обещает устойчивость ко взлому, фишингу и прочим ужасам современного ИТ-мира. Прошлый мой подход к юбикам окончился полной неудачей из-за кривого софта, драйверов и в общем-то моим нежеланием разбираться во всей этой мешанине букв и аббревиатур. Но тут отступать оказалось некуда, поэтому пришлось разбираться.
Итак, для начала. Если вы это делаете для себя, то берите минимум (подчеркиваю, минимум) два юбика. Дело в том, что юбики из-за природы своей не бекапятся, не обновляют прошивку и так далее и тому подобное. Если вам это вручили на работе, то вся боль по поводу работоспособности юбиков совершенно не ваша забота.
В общем, для начала надо заиметь свой юбик и поставить на комп Yubikey Manager. Ставим, запускаем, втыкаем ключ и вы должны увидеть что-то подобное этому:
Если увидели, то хорошо. Не увидели – дальше нет никакого смысла продолжать, надо разбираться, почему оно не алле.
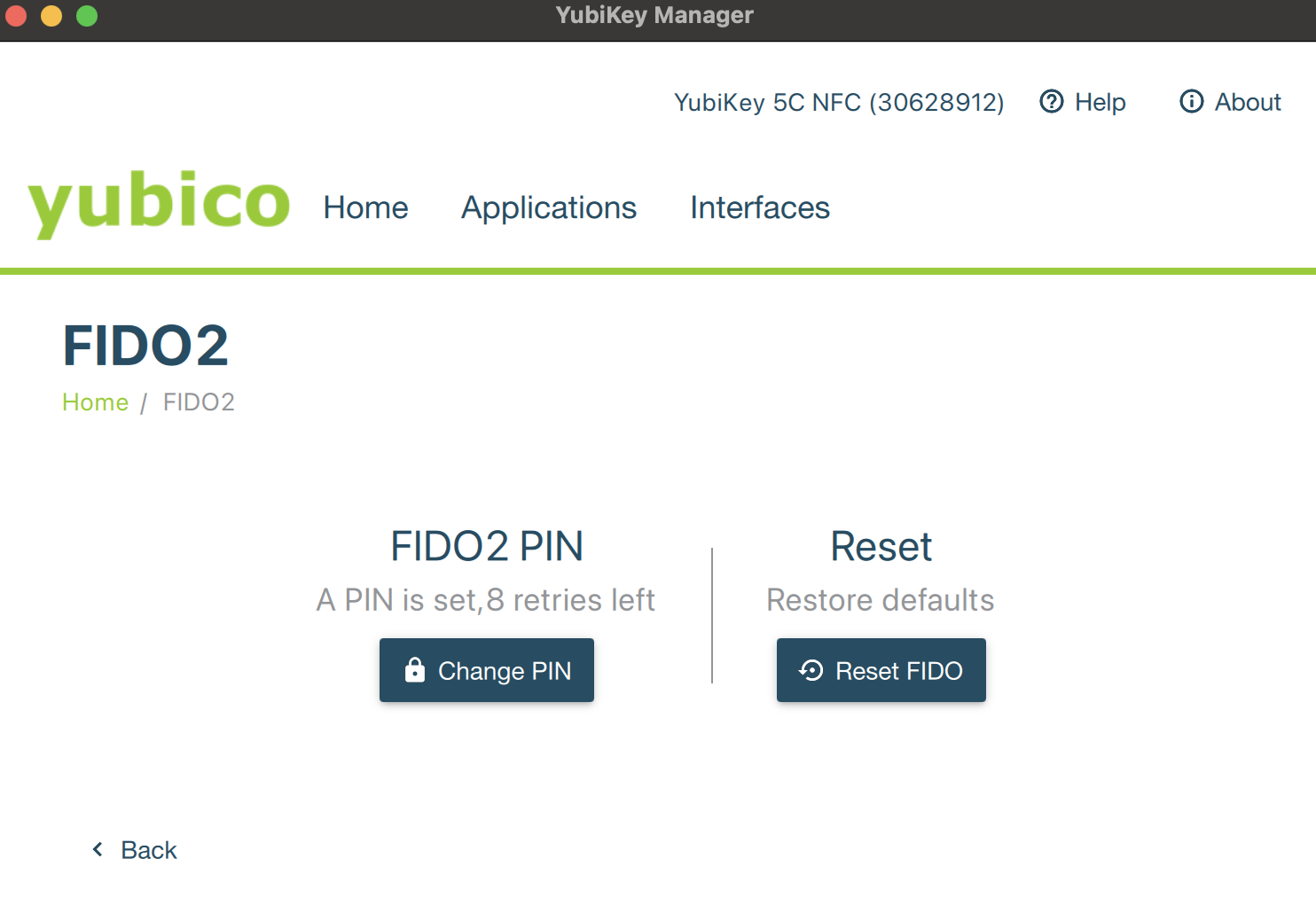
Так как я хочу для начала настроить ssh, то (тут пропущено часов Н чтения мануалов и страничек) сходить на вкладку Applications – FIDO2 и нажать на кнопачку Change Pin. Ибо стандартный пин 123456 совершенно не секурный и вообще. После смены пина должно получиться следующее:
Ну а теперь самое интересное: необходимо сделать новый ssh ключ. Старые не подойдут, но в общем-то и не очень и хотелось. И тут внезапно появляется выбор: какой ключ делать? Если по типу шифрования вопросов нет – только ed25519, то вот резидентный или не резидентный ключ генерить…
Немного погуглив, я выяснил, что Discoverable Credential или Resident ключ – это тот, который полностью хранится в памяти ключа. А вот Non-Resident – это хранение ключей как обычно, в файликах, но без юбика они бесполезны. В чем проблема? Если у вас resident ключ и у вас сперли юбик, то злой дядька хакер сможет ходить на ваши сервера как к себе домой. Надежда на пин-код слабая, ибо подсмотреть его как нефиг делать. А если у вас non-resident ключи, то вам нужно будет таскать файлики ключей по своим рабочим машинкам. Выбирать вам. Лично я тут топлю за non-resident.
Далее все совершенно стандартно. Генерим ключ (ВНИМАНИЕ! -O resident тут сами понимаете для чего)
ssh-keygen -t ed25519-sk -O resident
… И копируем получившийся id_ed25519_sk.pub по нужным местам. Тут процедура тоже совершенно стандартная и описана 100500 раз везде.
В общем-то почти все. Набираем ssh user@host и получаем… облом по полной. Полное впечатление, что ssh тупо завис. Однако это не так, ssh просто ждет касания ключа, только почему-то не пишет об этом. Если оно горит (мне нет), то опять гуглим. Оказывается, если у вас для ssh есть обычные ключи и они уже добавлены в ssh-agent (вот тут не уверен), то для нового ключа ssh ничего решает не спрашивать. Правим .ssh/config
И пробуем снова. У меня получилось и он стал спрашивать. Так как я делал resident ключ, то теперь радостно размахивая шашкой, удаляю все честно нагенеренное, имитируя новую машину. Или после ребута. Смотрим, какие есть ключи
Вот. ED25519-SK это тот, что “спрятан” в юбике. Пробуем ходить по ssh… ходится! На этом этапе можно начинать бросать чепчики в воздух и кричать “ура!”.
Ну и на всякий, ssh-keygen -K “вытащит” из юбика публичный ключ прямо в текущий каталог. Правда, получившийся приватный ключ получится фейковым non-resident и все равно, без юбика ничего работать не будет.
В общем, долго ли, коротко, но перевел я свою домашнюю сеть на совершенно классическую схему с выделеным роутером. На нем поднял связность с другими, вот это все. А значит что? Правильно, надо отрубить у кинетика функции роутера и оставить его в режиме контроллер меш-сети.
Делается это в общем-то просто. Отрубаем “интернет провайдера”, расставляем порты, прописываем в вебморде роутинг и ДНС сервера… И внезапно обнаруживаем, что работает все, кроме так называемой службы ndss. Она отвечает за обновления и прочие штуки.
В общем, оказалось, что чтобы эта служба заработала, надо вручную, через консоль, еще раз прописать роутинг. Пруф
(config)> show ip route
================================================================================
Destination Gateway Interface F Metric
================================================================================
0.0.0.0/0 192.168.99.1 Home U 0
192.168.99.0/24 0.0.0.0 Home U 0
(config)> ip route default 192.168.99.1 Home
Network::RoutingTable: Added static route: 0.0.0.0/0 via 192.168.99.1 (Home).
(config)> show ip route
================================================================================
Destination Gateway Interface F Metric
================================================================================
0.0.0.0/0 192.168.99.1 Home U 0
192.168.99.0/24 0.0.0.0 Home U 0
Ничего же не изменилось, да? А в реальности все заработало. Криводелы…
Вы не поверите, но снова подтвердилась теория о том, что компьютеры обладают душой. Стоило мне написать предидущий пост, как ubuntu совершила самоубийство. Я просто закрыл ноутбук и он больше не вышел из сна. И потом вообще отказался загружаться – даже груб не мог запуститься.
В общем, буквально пара дней и у меня появилась почти удовлетворяющая меня система. И более того, в случае чего я могу повторить ее буквально за несколько минут. Всякие мелочи типа скорости курсора и прочее пока приходится настраивать руками.
Как-то в очередной раз меня задолбала убунта своими приколами. Уже не помню, чем конкретно, но то, что задолбала – помню (смаил). И решил я устроить очередной чес по интернетикам на тему “а не придумали ли чего-то нового”. И, внезапно, индеец Джо обнаружил что у барака нет одной стены! В смысле оказалось что придумали, да еще как придумали!
Когда я первый раз прочитал про NixOS, я почему-то совершенно не поверил прочитанному. Ну согласитесь, все мы любим изредка приукрашивать действительность. А тут декларируют полную развязку системы и пользователя. Дескать, можно одной командой сменить Gnome на KDE и потом сделать так, чтобы от гнома и следов не осталось. Или если что-то накосячил в системе, то бах и вернуться на предидущее состояние. Или на пред-пред-предидущее. Уже хорошо, да? А следом еще одна плюшка: все состояние системы описывается в текстовых файлах. И контрольный в голову: они заранее подумали, что надо работать на линуксах, макосях и WSL. И обещают кросс-платформенное управление домашним каталогом.
В общем, начитался я интернетиков и пошел ставить эту nixos. Первая попытка получилась на удивление удачной. Воодушевившись, я пошел пробовать остальные фичи… И закопался напрочь. Я пробовал раз за разом, но мануалы в духе “рисуем два овала и потом дорисовываем так, чтобы получилась сова” не очень способствовали успеху. Я бы плюнул и списал на “да это еще один дистрибутив для повернутых”, но первая фича работала как железный лом. Чтобы я не делал, как бы не издевался над системой, но я всегда мог откатиться на любое число шагов назад. Единственное, чего она не переживала – это форматирование дисков 🙂
В общем, ниже очень краткая выжимка из кучи мануалов. В результате вы получите голую систему, то, что в других дистрибутивах называют minimal.
Шаг первый: идем на nixos.org и качаем минимальный исошник. Можно попробовать с графикой, но он у меня под виртуалбоксом не запустился почему-то.
Шаг второй: грузимся с этого исошника. Получаем консоль, в которой можно руками настроить сеть (про wifi пока не пробовал, но по ethernet все получается автоматом).
Шаг третий: меняем пароль root и цепляемся в систему снаружи.
Шаг четвертый: размечаем диски. Я ленивый, поэтому использую btrfs на весь диск. А дальше – сабволумами.
Все. За исключением первых строчек, которые нужны исключительно для btrfs и выдраны мной из хаутушки, остальные понятны с первого взгляда.
Просто говорим, что пользователь kiltum обычный юзер, хеш его пароля вот такой, и он входит в группу wheel. Далее включаем ssh и указываем публичные ключи для kiltum и root.
Нет, это реально все. После команды nixos-install --no-root-passwd случится вся магия. Оно пойдет, накачает чего-то, надрыгает винтом, пошумит кулером и вывалится назад в консоль. Можно смело ребутить и вытаскивать то, с чего грузились.
Загрузившись, потыкался и понял, что мне опять приходится вводить пароль на sudo. Надо убрать. Читаем доки (ведь надо по-правильному), там пишут, что надо добавить security.sudo.wheelNeedsPassword = false; в /etc/nixos/configuration.nix . И потом sudo nixos-rebuild switch.
Все, запрос пароля пропал. Но если вы сейчас перезагрузитесь, то обнаружите в бутменю два варианта. В последнем запроса пароля не будет, а в предпоследнем – будет. Мелочь? Да. Но это абсолютно точно так же работает и для всего другого. Добавляем следующее:
Пересбор конфигурации и у нас KDE. Не понравилось? Можно спокойно вернуться в Gnome или в голую систему. Самое оно для “попробовать что-то другое, но не ломая существующее”. Раньше я такое мог получить только с помощью снапшотов. А тут … магия! 🙂
И, внезапно, вот все вот это выше написанное, типа разбивки дисков можно делать автоматом. Просто скормив в инсталлере длинную строку с урлом репы. Примеры я видел, но пока такой магии не научился. Зачем? Ну если есть куча хостов, то ситуации класса “вылетел диск? Надо вернуть все как было” или “сделай мне еще точно такой же” решаются за столько времени, сколько надо для похода к этому хосту и вставки исошника.
Есть ли минусы? Есть конечно.
Самый главный: вам нужен интернет. Много. Нет, там можно как-то и без него, но это как с гентой: пока все нужное выкачаешь, уже забудешь, что хотел.
Второй: оно реально сложное для первоначального старта. Кажущаяся легкость разбивается о твердые грани хотелок. Но поднимать таким макаром хосты (пока тестовые) у меня получается уже быстрее, чем из темплейта и потом проходить ансиблом.
Остальное… Скажу так, слишком пока неоднозначное для меня.
Внезапно (тм) я обнаружил, что пользователям, которые сидят за кинетиком, не достается ipv6. Хотя сам кинетик исправно получает ipv6 и отображает его в дашборде. Немного погуглив, я обнаружил, что одной подсетки /64 кинетику мало, ему надо еще отдать некий prefix description.
Итак, схема соединения простая router - keenetic - user.
Роутер совершенно честно получает 2001:db8:99:0:52ff:20ff:fe7d:5d71 и показывает этот же адрес у себя в дашборде. И вот тут у меня возник затык. Везде рецепты по получению этого самого PD приводили к каким-то шаманским пляскам с systemd-network и прочим вещам. Естественно, роутеру на это было совершенно монопенисуально. В итоге индеец зоркий глаз обнаружил, что ISC DHCPD умеет отдавать этот самый PD.
Я вырезал лишнее. Если кратко, то вся суть в последних трех строчках. DHCPD садится на интерфейс, содержащий адрес из подсети 2001:db8:99::/48 и говорит, что любой обратившийся может взять префикс /56 из диапазона 2001:db8:100:100-200
Перезапускаем и тут же получаем в логах следующее
Sep 04 14:36:19 router-wifi dhcpd[2060]: Rebind message from fe80::52ff:20ff:fe7d:5d71 port 546, transaction ID 0x4E15F400
Sep 04 14:36:19 router-wifi dhcpd[2060]: Reply PD: address 2001:db8:100:200::/56 to client with duid 00:03:00:01:50:ff:20:7d:5d:71 iaid = 1 valid for 150 seconds
Sep 04 14:36:19 router-wifi dhcpd[2060]: Sending Reply to fe80::52ff:20ff:fe7d:5d71 port 546
Идем в дашборд кинетика и видим появившуся строчку IPv6 prefix
И клиент тоже подтверждает, что он получил айпишник из этого префикса
2: wlp0s20f3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 68:3e:26:b0:b1:93 brd ff:ff:ff:ff:ff:ff
inet 192.168.1.128/24 brd 192.168.1.255 scope global dynamic noprefixroute wlp0s20f3
valid_lft 215sec preferred_lft 215sec
inet6 2001:db8:100:200:fd6c:e8a9:6e3:7d75/64 scope global temporary dynamic
valid_lft 134sec preferred_lft 84sec
inet6 2001:db8:100:200:ae30:1497:47c9:c0e7/64 scope global dynamic mngtmpaddr noprefixroute
valid_lft 134sec preferred_lft 84sec
inet6 fe80::8e0b:e946:d9e4:9dfd/64 scope link noprefixroute
valid_lft forever preferred_lft forever
И теперь самое сложное: дать роутеру понять, куда надо роутить трафик для 2001:db8:100: . Вот тут я нормальных решений не нашел. Кинетик не умеет в динамические протоколы роутинга, а городить некий парсер логов и потом править роуты мне стало откровенно лень. Как делают большие пацаны из телекомов я тоже не нашел. Поэтому я взял и захардкодил это в роуты
routes:
- to: "2001:db8:100::/48"
via: "2001:db8:99:0:52ff:20ff:fe7d:5d71"
on-link: true
Да, криво. Да, может сломаться, если кто-то еще в этой сети попросит PD. Но, повторюсь, других вариантов я не нашел.
Ну а дальше наслаждаемся нормальным ipv6 и прочими положенными плюшками
Для осуществления старой мечты про свой собственный модемный пул со 100% дозвоном мне потребовалась АТС. Поначалу я планировал воткнуть в нее два модема, поперезваниваться и успокоиться. Однако стоило приехать старой аналоговой, как мне уже захотелось получить дозвон с V.90. А это значит, что одним аналогом не обойтись и требуется уже цифра.
Цифра так цифра. Немного поискав на просторах интернета, я обнаружил продаваемые в большом количестве АТС Panasonic NCP 500/1000. Еще немного погуглив, прикинул список необходимых плат в ней для моего развлечения и заказал наиболее подходящую.
Для пытающихся повторить мой путь: необходима плата PRI30, по которой будет идти цифровой поток в cisco 5350 (она внизу, там платы 2PRI и NP60 – тоже очень широко распространенный бандл) и SLC8/16 (в нее будут вставляться аналоговые модемы и прочие телефоны).
Следующий вопрос, который необходимо решить: как настроить/узнать настройки АТС? И вот тут внезапно для любого ИТшника встает сразу несколько проблем. Самая главная в том, что телефонисты – это такие заносчивые и высокомерные индюки, которые хрена-с-два поделятся информацией. И фиг бы на них, но и официальная документация от самого панасоника представляет из себя лютейший фейспалм с кучей ошибок. В общем, если ты был на курсах и тебя научили как тыкать по менюшкам, то ты молодец. Остальные – быдло, достойные только для того, чтобы их поунижать. По большей части, этот пост родился благодаря таким телефонистам.
Итак, для начала достаем из станции SD карту и делаем бекап на всякий случай. Если изучить файлики, то становится понятно, что там лежит вся конфигурация АТС вместе с дополнительными лицензиями (если они были).
Теперь про пароли. Вроде можно вручную найти нужное в DBSYS, но мне лень и я отыскал программку KXTDA_password_recovery. Ей скармливаешь этот файлик и она выдает пароли, которые поставил ваш предшественник. Иногда это что-то сложное, но чаще это стандартные 1234 (на двух из трех АТС у меня было так).
Узнав пароли, засовываем карту назад в АТС. Но пока не включаем. Нужна программа для настройки. Она лежит в архиве UPCMCv7.8.1.1_R15.zip. Распаковываем, ставим и она спросит про ключ. Тут уже постаралась сама panasonic. Чтобы подсадить “инсталляторов атс” на толстую… ну пусть будет иглу, она требовала ежегодной дани от своей паствы. Прошедшие курсы получали дырку, через которую могли генерить эти ключи в количестве аж двух штук в год (если форумы не врут). Мы же просто воспользуемся программкой upcmc_kg_2024.exe, которая генерит ключи на 2024 год. Рядом лежит она же, но генерящая ключи на 2025й. Когда наступит 2026, то просто сравните побайтно эти программки, найдите один байт разницы и увеличьте его на еденицу.
Ок, программа поставилась, и согласна соединяться. Но куда и с чем? С этим тоже все просто: вставляем сетевой кабель в LAN, запускаем tcpdump или wireshark и включаем станцию. Немного помигав лампочками, она включит свой ethernet и согласно всяким стандартам, бросит ARP запрос на предмет совпадения ядреса. Ну и естественно, скажет свой. Хоть станция и умеет в DHCP, но телефонисты в него не умеют, поэтому везде рекомендуют ставить статику, так что в 99,99% вы не увидите bootp запросов. Ну а дельше дело техники: на компе настраиваем любой адрес из той же подсети и можно подключаться.
Теперь единственное, что может вас остановить, это регистр. Нет, я не шучу и програмисты-телефонисты настолько тупые, что не осилили функцию strup/strlow. Так что вводить INSTALLER надо исключительно в верхнем регистре. Я на этом пару раз погорел. Хорошо, что хоть пароль из цифр (в буквы они тоже не любят).
Дальше проблем нет. Программа открывает вам все потроха станции и вы можете изучить, что оставил вам ваш предшественник. Скажу сразу, будет немного больно, ибо для ИТшника настройки разбросаны хаотически и чтобы получить даже простую фигню типа “входящий звонок приходит сразу на несколько телефонов” надо попрыгать по нескольким экранам.
Но, если вы дочитали до этого момента, то есть способ завести АТС еще проще (на всякий: лицензии не пропадут). Сделав бекап, просто включите АТС с передвинутым влево, на SYSTEM INITIALIZE, движком. Подождите, пока светодиодик RUN замигает и передвиньте назад, на NORMAL. Все, теперь АТС на порту LAN будет ждать вас по адресу 192.168.0.101. После подключения вас спросят про пару глупостей и предложат настроить все по-минимуму. Говоря проще, программка раскидает телефонные номера согласуясь со вставленными картами слева-направо и сверху-вниз. Все, вы можете втыкать телефоны, перезваниваться и выходить в город “через девятку”. Конечно, если у вас есть плата для внешних линий LCOT.
Ну а теперь остается только читать документацию, сравнивать с тем, что можно в реальности и шариться по остаткам форумов. Как я писал выше, можно даже не регистрироваться – все равно толку не будет.
А теперь то, что я уже обнаружил.
Во-первых, забудьте про порт MNT. Да, это ethernet, да в инструкции написано, что можно через него администрировать АТС. Врут. На этом порту никогда ничего не появляется. Ни при ресете, ни при инициализации, ни при работе. Пусто и глухо. Так что только LAN.
Потом, кнопочка Reset – это просто выключение-включение питания. Сделали поблажку, ибо на морде атс всегда висит пучок кабелей и добраться до выключателя сзади проблематично.
Следом: если у вас атс NS (там все, окромя прошивок, подходит от NCP), то никогда не дергайте ее по питанию! Погромисты из панасоника не осилили повторить то, что они сделали в NCP и очень велик шанс все угробить на SD карте.
Ну и наконец, вот вам ссылочка https://tygh.ru/s/iiwLyPKpzGESZCX , куда я выложил все то, что на данный момент нарыл для панасоника. Включая вышеупомянутые программки. Да, там есть дубликаты в доках, но мне пока лень их вычищать.
Достал я тут из закромов чудного зверька, с которым раньше не сталкивался. Cisco 881G. Маленькая настольная коробочка с двумя антеннами и 5 ethernet портами. Если на езернеты мне было пофиг, то вот антеннки возбудили мое любопытство.
Оказалось, что в этой коробочке спрятали 3G модем, совмещенный с GPS. Ну и роутер в довесок.
Ок, цепляюсь к коробочке кабелем и смотрю, что там в наличии отсутствия.
show flash
copy flash:c880data-universalk9_npe-mz.153-3.M.bin tftp://100.64.1.1
Такой версии IOSа в моей коллекции честно спертых нет, поэтому ныкаем поближе.
Ладно, вытаскиваю коробочку на окно и смотрю, к чему прицепился модем
Router#show cellular 0 network
Current Service Status = Normal, Service Error = None
Current Service = Combined
Packet Service = HSPA (Attached)
Packet Session Status = Inactive
Current Roaming Status = Home
Network Selection Mode = Automatic
Country = RUS, Network = ROSTELEC
Mobile Country Code (MCC) = 250
Mobile Network Code (MNC) = 20
Location Area Code (LAC) = 28600
Routing Area Code (RAC) = 202
Cell ID = 34499
Primary Scrambling Code = 329
PLMN Selection = Automatic
Registered PLMN = , Abbreviated =
Service Provider = ROSTELECOM
Router#show cellular 0 radio
Radio power mode = ON
Current Band = WCDMA 2100, Channel Number = 10612
Current RSSI = -90 dBm
Band Selected = Auto
Number of nearby cells = 1
Cell 1
Primary Scrambling Code = 0x149
RSCP = -91 dBm, ECIO = -5 dBm
Все верно. Мне выдали вместе с GPON симку от “Ростелеком”, вот он туда и прицепился. Курю маны, читаю старые архивы. Гуглю… В общем, прошло пара дней. Теперь вы можете быстренько пробежаться вместе со мной. Если что, у коробочки есть встроенный веб-сервер, но он сделан на технологиях 2000х годов и современные браузеры в нем только статус могут показать.
Первым делом создаю профаил для модема, куда ему цепляться. Подозреваю, что укажи я не правильный APN, он все равно бы прицепился, но вдруг.
cellular 0 gsm profile create 1 internet.rtk.ru chap rtk rtk
Теперь конфигурируем, конфигурируем и заканчиваем конфигурировать. Подозреваю, что есть лишние ошметки, но это рабочая конфигурация. Болдом – то, что я вводил. Остальное оно само.
cisco-881G#show run
Building configuration...
Current configuration : 2041 bytes
!
! Last configuration change at 12:11:05 UTC Sun Aug 18 2024
! NVRAM config last updated at 12:11:07 UTC Sun Aug 18 2024
! NVRAM config last updated at 12:11:07 UTC Sun Aug 18 2024
version 15.3
no service pad
service timestamps debug datetime msec
service timestamps log datetime msec
no service password-encryption
!
hostname cisco-881G
!
boot-start-marker
boot-end-marker
!
!
enable password cisco
!
no aaa new-model
!
!
!
no ip dhcp use vrf connected
!
!
!
ip cef
no ipv6 cef
!
!
multilink bundle-name authenticated
chat-script hspa-R7 "" "AT!SCACT=1,1" TIMEOUT 60 "OK"
!
!
license udi pid C881G+7-K9 sn FCZ1806C3EH
license boot module c880-data level advipservices_npe
!
!
!
!
controller Cellular 0
gsm sms archive path tftp://100.64.1.1/SMS
gsm gps mode standalone
gsm gps nmea
!
ip tftp source-interface Vlan1
!
!
!
!
interface FastEthernet0
no ip address
!
interface FastEthernet1
no ip address
shutdown
!
interface FastEthernet2
no ip address
shutdown
!
interface FastEthernet3
no ip address
shutdown
!
interface FastEthernet4
no ip address
shutdown
duplex auto
speed auto
!
interface Cellular0
ip address negotiated
ip nat outside
ip virtual-reassembly in
encapsulation slip
history BPS
dialer in-band
dialer idle-timeout 0
dialer string hspa-R7
dialer-group 1
async mode interactive
!
interface Vlan1
ip address 100.64.1.4 255.255.255.0
ip nat inside
ip virtual-reassembly in
!
ip forward-protocol nd
ip http server
no ip http secure-server
!
!
ip nat inside source list 1 interface Cellular0 overload
ip route 0.0.0.0 0.0.0.0 Cellular0
!
dialer-list 1 protocol ip permit
!
access-list 1 permit 100.64.1.0 0.0.0.255
!
control-plane
!
!
!
line con 0
password cisco
login
no modem enable
line aux 0
line 3
script dialer hspa-R7
modem InOut
no exec
rxspeed 21600000
txspeed 5760000
line 6
modem InOut
no exec
transport input all
transport output all
stopbits 1
speed 4800
line vty 0 4
password cisco
login
transport input all
!
ntp source Cellular0
ntp master 1
ntp update-calendar
!
end
Конфигурация следующая. 100.64.1.4 – это адрес циски. Работает только порт 0. Всё, что приходит с 100.64.1.0/24 – натить в интернет через сотовый модем. Ну и попутно включить GPS и попытаться брать с него время.
В чем была проблема? Я никак не мог поднять интерфейс модема. Он радостно сообщал, что включен, но адрес от провайдера получать категорически отказывался. В статусе было, что он занимается спуфингом. Покурив интернеты еще раз, я обнаружил, что достаточно добавить в line 3 строку про modem inout, как все тут же зажурчало, как и положено. Почему ее нет ни в одном официальном гайде циски про 880е – я не знаю. И почему dialer idle-timeout 0 игнорируется до первого подьема – я тоже не знаю.
В общем, вот лог успешной пробы. Исторический момент, так сказать.
#ping 8.8.8.8
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 8.8.8.8, timeout is 2 seconds:
...
*Aug 18 10:55:41.267: %LINK-3-UPDOWN: Interface Cellular0, changed state to up
*Aug 18 10:55:42.267: %LINEPROTO-5-UPDOWN: Line protocol on Interface Cellular0, changed state to up.!
Success rate is 20 percent (1/5), round-trip min/avg/max = 84/84/84 ms
Вот он, исторический момент. Сработало все, хотя и 4 пакета потерялись, пока модем поднимался. А что насчет смс? Отправляю себе на телефон и отвечаю.
# cellular 0 gsm sms send 8926295хххх "Test from cisco"
Aug 18 11:55:37.691: %CELLWAN-5-INCOMING_SMS: Cellular0 has just received new incoming SMS.
#cellular 0 gsm sms view all
SMS ID: 0
TIME: 24/08/18 16:00:01
FROM: 7926295хххх
SIZE: 4
^D^^^D:
--------------------------------------------------------------------------------
SMS ID: 1
TIME: 24/08/18 16:09:39
FROM: 7926295хххх
SIZE: 7
Privet
--------------------------------------------------------------------------------
Ну с смс тут все очень кондово. Первая смс это “Ок” на русском. Ладно, а что с GPS?
#show cellular 0 gps
GPS Info
-------------
GPS State: GPS acquiring
GPS Mode Configured: standalone
GPS Error Count: 0
Latitude: 0 Deg 0 Min 0 Sec North
Longitude: 0 Deg 0 Min 0 Sec East
Timestamp (GMT): Sun Jan 6 00:00:00 1980
Fix type index: 0
Satellite Info
----------------
Satellite #11, elevation 0, azimuth 0, SNR 26 *
Satellite #20, elevation 0, azimuth 0, SNR 24 *
Satellite #6, elevation 0, azimuth 0, SNR 19 *
А вот с GPS все плохо. С трудом нашла 3 спутника, хоть и стоит на окне и близко к стеклу. Да и у тех уровень сигнала около плинтуса. Вот она, корпоративная надежность! Рядом лежащий usb GPS приемник за 300 рублей видит кучу и совершенно ничем не смущается. Обидно.. надо подумать, как там антенну поближе вытащить или сделать ее побольше. Ибо хочу свой NTP сервер со стратумом 1 и все тут!
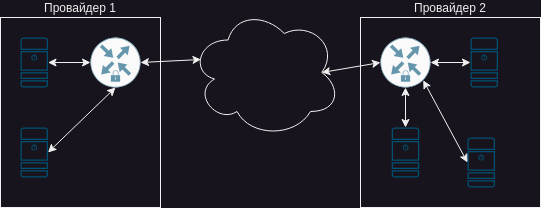
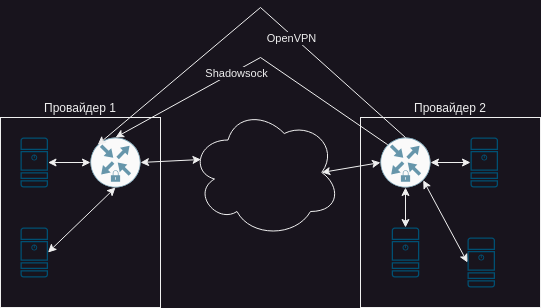
Недавно мне потребовалось соеденить две площадки с виртуалками. Обе у нас (ПОДЧЕРКИВАЮ!), обе у достаточно крупных провайдеров. В общем, надо сделать так, чтобы Н машин у одного провайдера видели М машин у другого. Трафик не большой, но достаточно критичный.
“ХА!” – сказал я и нарисовал классическую схему соединения.
Выделяем на каждой площадке машинку (или на одну из доступных вешаем внешний ip), обвешиваемся файрволами и закрываем трафик тем же IPSec. Инструкций много, вариантов много – в общем, прорвемся!
Быстренько собрал, накидал конфиги и получил веслом по морде. Протокол ESP где-то по пути заблокирован. Техподдержка обоих провайдеров клянется, что это не у них, но ipsec не верит и отказывается подниматься. Ладно, хотелось по-корпоративному, пойдем по-молодежному.
OpenVPN шустро поднялся, поначалу начал бодро гонять трафик, но через некоторое время начались проблемы. Он переподсоединялся, слал немного байт и снова уходил в нирвану. Смена протокола с UDP на TCP приносила лишь временное облегчение.
Кто виноват – мне, если честно говорить, абсолютно пофиг. Мне трафик нужно гонять. Поэтому расчехлил тяжелую хипстерскую артиллерию – shadowsocks + v2ray. Качаем с гита, просто распаковываем, плюем в конфиг сервера следующее (1.1.1.1 – это внешний адрес сервера, если что):
Запускаем и получаем на клиенте socks5 сервер на 1080 порту. А теперь – финт конем. В конфиг OpenVPN на клиенте добавляем одну единственную строчку:
socks-proxy 127.0.0.1 1080
Ну и перезапускаем все, чтобы прочитало конфиги. Вуаля! У нас получилась следующая схема:
OpenVPN ходит через ShadowSocks, который ходит через хрен знает как настроенный интернет.
Но через некоторое время проявилась та же самая боль: немного погодя клиент терял соединение с сервером. Причем перезапустишь – все снова начинает бегать. Ставил опции ping, менял MSS и MTU – пофиг: рандомно теряем коннект.
Ок, перевел openvpn и shadowsock на TCP. Всё магически исправилось. Коннект стабильный, не рвется, пакетики бегают туда-сюда.
Отключил "mode": "tcp_and_udp", позакрывал фаирволлами и начал тестить.
Итак, прямой tcp линк безо всяких штук
[ 1] 0.0000-10.2561 sec 112 MBytes 91.8 Mbits/sec
Да, клиент сидит на дешевом тарифном плане в 100 мегабит, поэтому практически упираемся в полку. Теперь через все эти навороты:
И это без какого-либо тюнинга! Да, tcp-over-tcp-over-tcp еще тот изврат, но ведь работает же! А после тюнинга (банальные буфера и прочее – в любом мануале по openvpn) я получил следующее:
Нам надо платить меньше. На одной стороне не нужен выделенный ip (а они нынче дорогие). Выпускают всех через SNAT и норм.
Настраивается не просто, а очень просто.
Снаружи на сервере порт OpenVPN можно спокойно закрыть фаирволлом. Соединение идет с локалхоста. Больше сесуретей богу сесурити!
Память не жрет. Можно смело брать самую дешевую виртуалку под “роутеры”. Вся вот эта машинерия + FRR с OSPF сьели 200 мегов.
Оно работает. Реально, за неделю уже не одиного разрыва.
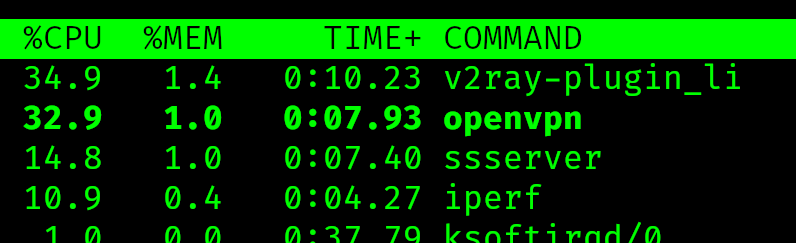
Что в минусах:
Потеряли в скорости. Немного, но есть. Проблема в том, что на стороне клиента я банально уперся в единственный ЦПУ виртуалки. Когда тесты идут, на той стороне в топе такое:
С другой стороны, там трафик в 20-30 мегабит уже редкость, так что в любом случае все в порядке. Но запас карман не тянет.
Ну и нафига я все это делал: мне нужно было среплицировать один MySQL в другой. Предложенная схема их удовлетворила, значит задача выполнена.
Слишком много серверов осталось на centos. И, внезапно, приходят странные заказчики, которым кровь из носу нужен именно centos и именно 7й версии. Поставить-то можно поставить, но где найти новые версии пакетов, ведь эти редиски грохнули имя mirror.centos.org?
Рецепт простой. Пока (пока!) работает такой рецепт
sed -i 's/mirrorlist/#mirrorlist/g' /etc/yum.repos.d/CentOS-* && sed -i 's|#baseurl=http://mirror.centos.org|baseurl=http://vault.centos.org|g' /etc/yum.repos.d/CentOS-* && yum update