Итак, со схемами в proteus наигрались, теперь голова полна идеями, хотелками и желалками. Но ни одна идея не реализуется сама собой, поэтому надо выбрать “движок” для нее.
Как выбирают контроллер?
Во-первых, по личным предпочтениям. Кому-то нравится одна архитектура, кому-то другая. У кого-то уже есть опыт с одними микроконтроллерами и ему лень изучать другие … Но я считаю, что раз опыта и предпочтений нет, поэтому – stm32. Вам на данном этапе все равно, а мне потом спасибо скажете.
Во-вторых, по скорости. Если задача сложная, то думаю понятно, что работающий на 72МГц контроллер обгонит работающего на 16МГц (грубо – у кого больше литраж у двигателя, тот быстрее разгонится или больше увезет). А если устройство работает от батареек, то наоборот, устройство работающее на 16МГц легко даст фору работающему на 72х (опять же, чем больше литров, тем чаще на заправку надо будет ездить). Но на данном этапе нам совершенно все равно, какая скорость у контроллера – для нас подойдет любая.
И наконец, по числу портов и их возможностями. Все порты делятся на два типа: цифровые и аналоговые. Цифровые оперируют уровнями типа “есть сигнал” и “нету сигнала”, а аналоговые – “какой уровень у сигнала?”. Говоря другими словами – кнопки, выключатели и прочие переключатели – это цифровые, а всякие регуляторы, измерители и прочее – аналоговые. На каждую кнопку, релюшку или измеритель надо по одному порту (конечно, есть куча возможностей, как от этого уйти, но пока нам этого не надо). И крайне рекомендую при выборе зарезервировать пару портов под всякие доделки и внезапно всплывшие идеи.
Ладно, хватит разговоров, пора выбирать то, на чем делать будем, а то очень охота в магазине денег потратить, пока еще есть возможность.
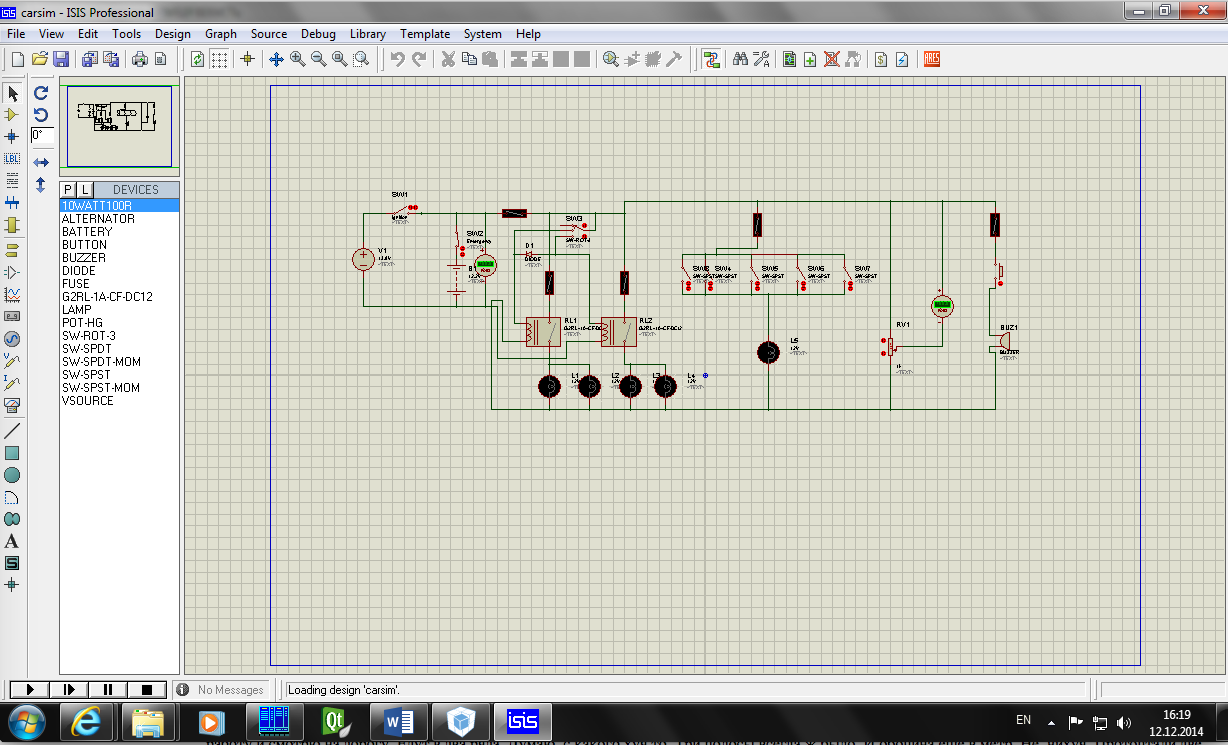
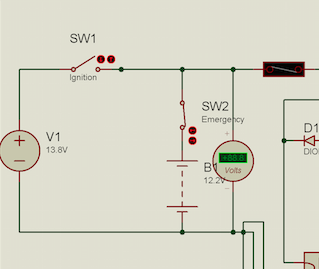
Что будем делать-то? В смысле для чего мы все это затеяли? Давайте начнем с простого. Пусть будет система автоматического включения света в машине. Как пример использования: садимся в машину, включаем зажигание, заводим машину и через некоторое время наш контроллер включает фары. Выключили зажигание – все выключилось. Сплошные бонусы: стартеру легче крутить двигатель – фары не отбирают лишних ампер и вам не надо будет помнить о включении фар.
Какой будет алгоритм работы?
1. Измеряем напряжение бортовой сети
2. Напряжение меньше 13В? если да, иди на п.1
3. Подождать 5 секунд.
4. Включить фары.
Все, никаких заморочек. Просто и совсем не страшно. Как видно, нам потребуется всего 2 порта: один аналоговый для измерения напряжения в сети и один цифровой, для управления релюшкой фар.
(отступление) Не хотите фары включать? Ну тогда например можно автоматически включать и выключать компрессор в пневмосистеме. Или в зависимости от температуры включать нагреватель или вентилятор. В общем, подойдет любой вариант “измерил что-то и как это что-то достило такого-то уровня – включил или выключил нечто”.
Вернемся к нашим баранам. Нам нужен микроконтроллер, у которого есть как минимум 1 аналоговый порт на вход и 1 цифровой порт на выход. Сейчас смешно, да. Но потом всего будет не хватать и начнутся мучения.
Теперь готовимся скачать много из сети. Для начала нам нужна программа STM32CubeMx. (Все поисковики ее легко находят, но вот прямая ссылка http://www.st.com/web/catalog/tools/FM147/CL1794/SC961/SS1533/PF259242?sc=stm32cube там мотайте страницу в самый низ и справа будет маленькая красная кнопочка Download).
Зачем нужна эта программа? Как я писал в первом посте, STM32 имеют один, но очень большой и неприятный минус – очень сложно начать с ними работать. В этих микроконтроллерах очень много возможностей и вариаций, поэтому даже просто запустить его составляет очень большую проблему. Команды инициализации, предназначенные для одной серии, не подходят для другой. Один и тот же порт может выполнять разные функции на разной частоте, причем все это настраивается в четырех или пяти местах. В общем, реальный кошмар после атмеловских контроллеров и 99% причин неработащих программ.
Вот и придумали этакий “генератор кода инициализации”, когда можно мышкой не торопясь повыбирать порты и их функции. При этом идет одновременный контроль правильности использования порта и непересечение его с другими функциями. В общем, скачивайте, распаковывайте и запускайте программу (может потребовать java, так что тоже ставьте). Как ставить программы, нажимая next, я рассказывать не буду 🙂

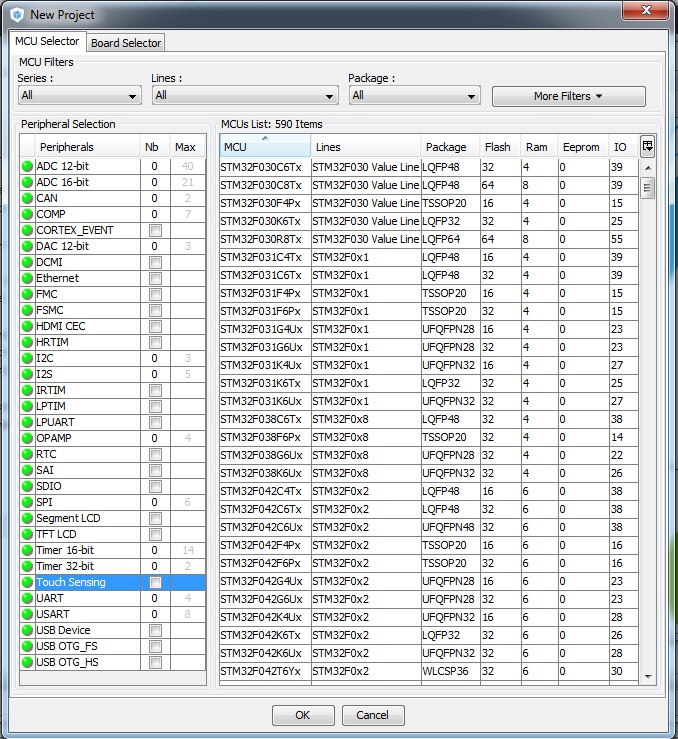
Перед вами откроется очень информативное окно. New Project – это создать новый проект, Load Project – загрузить старый, который редактировали раньше. Нам естесственно надо выбрать создать новый. И тут …
И тут перед вами откроется окно, в котором собрана вся (почти) линейка микроконтроллеров. Первая вкладка – MCU Selector позволяет выбрать подходящие контроллеры в их голом виде. Слева в табличке функционал, справа – подходящие контроллеры. Скажем, нужно нам в нашем проекте использовать одновременно ethernet и часы реального времени, так значит ставим галочки и получаем, что нам подходят 88 микроконтроллеров из 590 (на момент написания). Но эта вкладка для продвинутых пацанов.
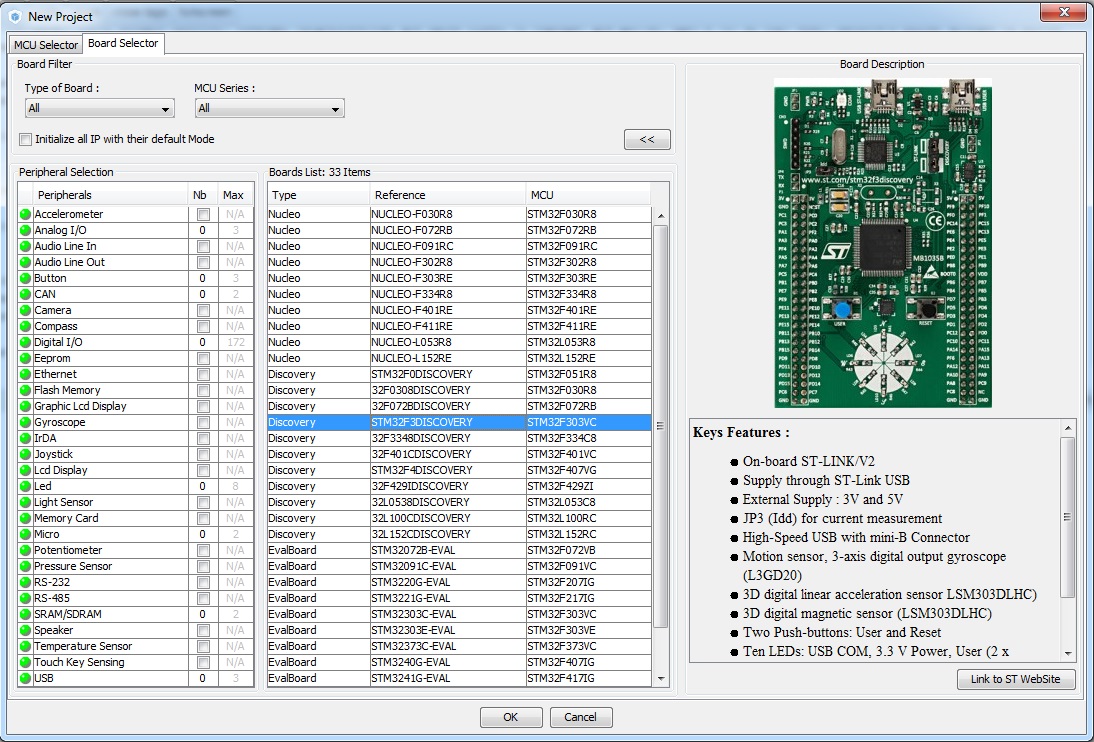
Нам нужна следующая вкладка, которая называется Board Selector. Тут уже можно выбрать готовые платы, со всем распаянным. Сразу рекомендую нажать кнопку “>>”, которая будет показывать изображение платы.
Механизм тот же самый – слева выбираем что хочется, а справа получаем список того, где это есть. Потом открываем веб-сайт ближайшего магазина электроники и смотрим на наличие и цену. Лично у меня есть платы STM32L100 и STM32F3 (именно она изображения на скриншоте). Так как F3 мне нравится больше, то и в дальнейшем я буду использовать именно эту плату. Но повторюсь, вы можете использовать любую плату или процессор – главное, что бы он вам подошел по характеристикам.
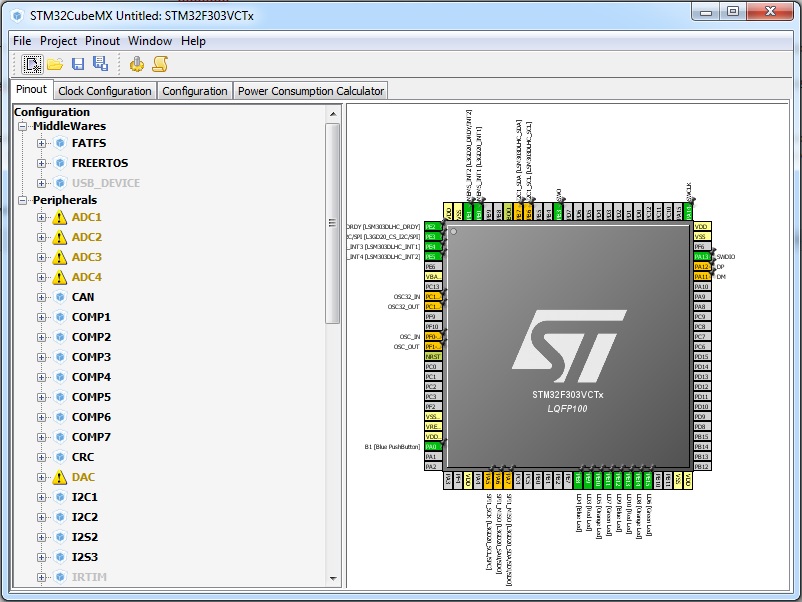
Выбрав плату или процессор, жамкаем на кнопоку ОК в самом низу. Компьютер немного подумает и потом выдаст примерно вот такую картинку.
Слева будут всякие возможности, которые умеет процессор, а справа – как и на что распределены ножки и процессора. Если вы вышли сюда из выбора плат, то программа сама показала, что на плате куда подключено. Как видите, все ножки помечены разными цветами.
Желтенькие и светлозеленые – ножки, назначение которых изменить нельзя. Питание, земля и прочие подобные ножки.
Оранживенькие – ножки, на которые повешено то, что есть на плате и что можно либо отключить, либо заиспользовать. У меня это кварцевые резонаторы, гироскоп с компасом, USB порт и так далее.
Зелененькие – это ножки, на которые тоже повешено то, что есть на плате, но это ТО – кнопки, светодиодики и прочее. Грубо говоря, отличие только в сложности с точки зрения контроллера. Таким же цветом будут обозначаться и ножки, которые вы выделили для вашего проекта.
Серенькие – свободные ножки, которые можно использовать.
“Пришпилленость” ножки означает, что программа не может менять ее назначение, как бы этого ей не хотелось. Дело в том, что если у вас нету предпочтения, какой именно порт для чего использовать, то программа постарается “раскидать” их так, что бы микроконтроллер был наиболее функциональным.
Как менять назначение ножек? Есть два способа. Первый – это просто мышкой ткните на ножке. Вот для примера я ткнул на ножке, которая у меня подключена к голубой кнопке.
Как видите, эта ножка может выполнять аж 17 функций, но сейчас она работает как GPIO_Input (я ниже объясню, что это значит).
А второй способ – воспользоваться левой вкладкой и включить нужную функцию.
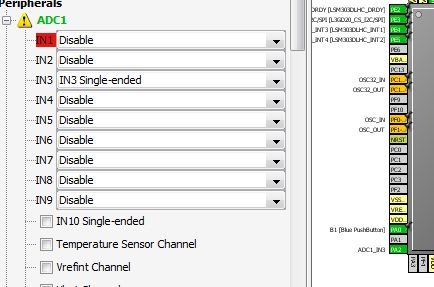
Как видим, у функции вообще горит желтый предупреждающий знак, который показывает, что что-то с ней не то. Открыв ее, можно увидеть подсвеченным красным подфункцию. В данном случае это IN1. Подведя мышку к красному, можно узнать, что с чем конфликтует. В данном конкретном случае можно увидеть, что 1й канал 1го аналого-цифрового преобразователя конфликтует на ножке процессора PA0, которая уже стоит в режиме GPIO_Input. Белиберда, да? Но ничего. Для примера можно обидеться и раз нам не дают использовать IN1, выбрать IN3, что бы это не значило. И обратите внимание, на рисунке процессора справа одновременно начнет показываться как “занятая” соответствующая ножка процессора. В нашем случае это PA3, в левом нижнем углу.
Дальше можно начинать включать те или иные функции, сообразуясь со своим мнением о прекрасном и расположением выводов на данной конкретной плате.
Итак, как же понять, какие функции можно повесить на ножку? Что бы не забивать голову, я опишу только наиболее нужные и часто используемые функции. Назначение других можете узнать сами, когда прижмет (но 90% это никогда не понадобится).
Итак, что можно выбрать?
ADC – Или АЦП, аналогово-цифровой преобразователь. Показывает значение напряжения. У большинства АЦП есть каналы, к которым он может подключаться. А каналы напрямую подключены к ножкам. То есть когда вам надо измерить напряжение на 1,2 и 3й ножке, то микроконтроллер на самом деле будет выполнять примерно следующее “подключить ацп к ножке 1, измерить, подключить ацп к ножке 2, измерить, подключить ацп к ножке 3, измерить”. В принципе, для большинства задач этого достаточно, ведь измерение одного канала занимает от 1 до 10 мс. Но есть задачи, когда необходимо реально одновременно измерить напряжение на несколких ножках. В таком случае используют два или больше АЦП. Например, в F3 серии аж 4 АЦП, поэтому мы можем измерять 4 уровня одновременно. Если мы заиспользуем все доступные ресурсы, то сможем за 0,1с измерить 59 аналоговых выводов (ардуинщики, вы рыдаете? :).
DAC – или ЦАП. Цифро-аналоговый преобразователь. Преобразует некоторое значение в уровень сигнала на выходе. Обычно один DAC имеет от 1 до 10 выходов, каждый из которых можно регулировать отдельно.
TIM – таймеры. Срабатывающие “раз в нное время” сигналы. На таймерах в stm делается очень многое – от PWM (управление сервомоторами и яркостью) до подсчета частоты смены сигнала на входе. Немножко к ним имеют отношение RTC – часы реального времени (которые считают минуты и секунды, а не тики и такты) и WDG – системы, которые автоматически перезагружают контроллер, если он завис, но я их касаться не буду
USART/UART – контроллеры для связи с “внешним миром”: с компьютерами, с другими контроллерами и так далее.
И наконец GPIO. Это порты общего назначения. То есть на них можно вешать все, что душе угодно. Они могут быть GPIO_Input – порт, работающий на вход (который принимает сигнал “есть” и “нет”) и GPIO_Output – порт, работающий на выход (который выдает сигнал “есть” и “нет”). Вы можете увидеть GPIO_Reset – это означает, что порт находится в хз каком стоянии и GPIO_EXTI – это выход прерывания. В общем лишнее на данном этапе.
Все ножки маркируются следующим способом: [подсистема]_[функция]. Пример:
ADC1_IN6 – 6й вход 1го АЦП контроллера
DAC1_OUT1 – 1й выход 1го ЦАП контроллера
USART1_TX – порт передачи 1 контроллера связи.
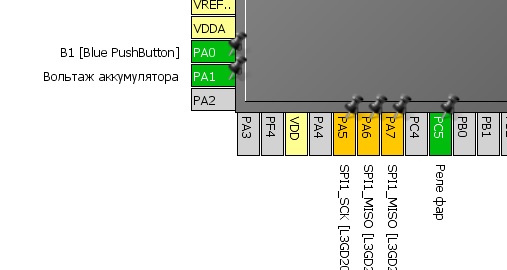
Но вернемся назад. Из всего выше перечисленного нам нужен один ADC ввод и один GPIO_Output вывод. Для ввода я заиспользую ADC1_IN2 (ножка PA1), а для вывода GPIO_Output – PC5. Они расположены на одной стороне реальной платы, поэтому мне будет удобно с ними работать. И что самое главное, они не конфликтуют ни с чем, что уже есть на плате.
Щелкаем и меняем назначение нужных нам ножек. Обратите внимание на то, что у PA1 нет булавки, а у PC5 – есть. Это та самая функция переназначения портов, когда вдруг функционал будет конфликтовать, а нам нет разницы, откуда его брать. Что бы “прикрепить” функционал к ножке, надо просто правой кнопкой мышки по ней щелкнуть и выбрать Signal Pinning. Теперь ни одна сволочь не отберет у нас ее :). Кстати, там же можно и дать название ножке, что бы не запутаться.
Согласитесь, так немного красивее? И так по всем ножкам-функциям, которые нам потребуются в нашем будующем устройстве. Не подходит что-то – возвращяемся назад и выбираем другую плату/микроконтроллер. Но я буду считать, что мы этот этап успешно преодолели и с большим трудом выбрали и назначили так нужные нам аналоговый порт на вход и цифровой порт на выход.
Можно сохранить проект на всякий случай, ибо это только начало.
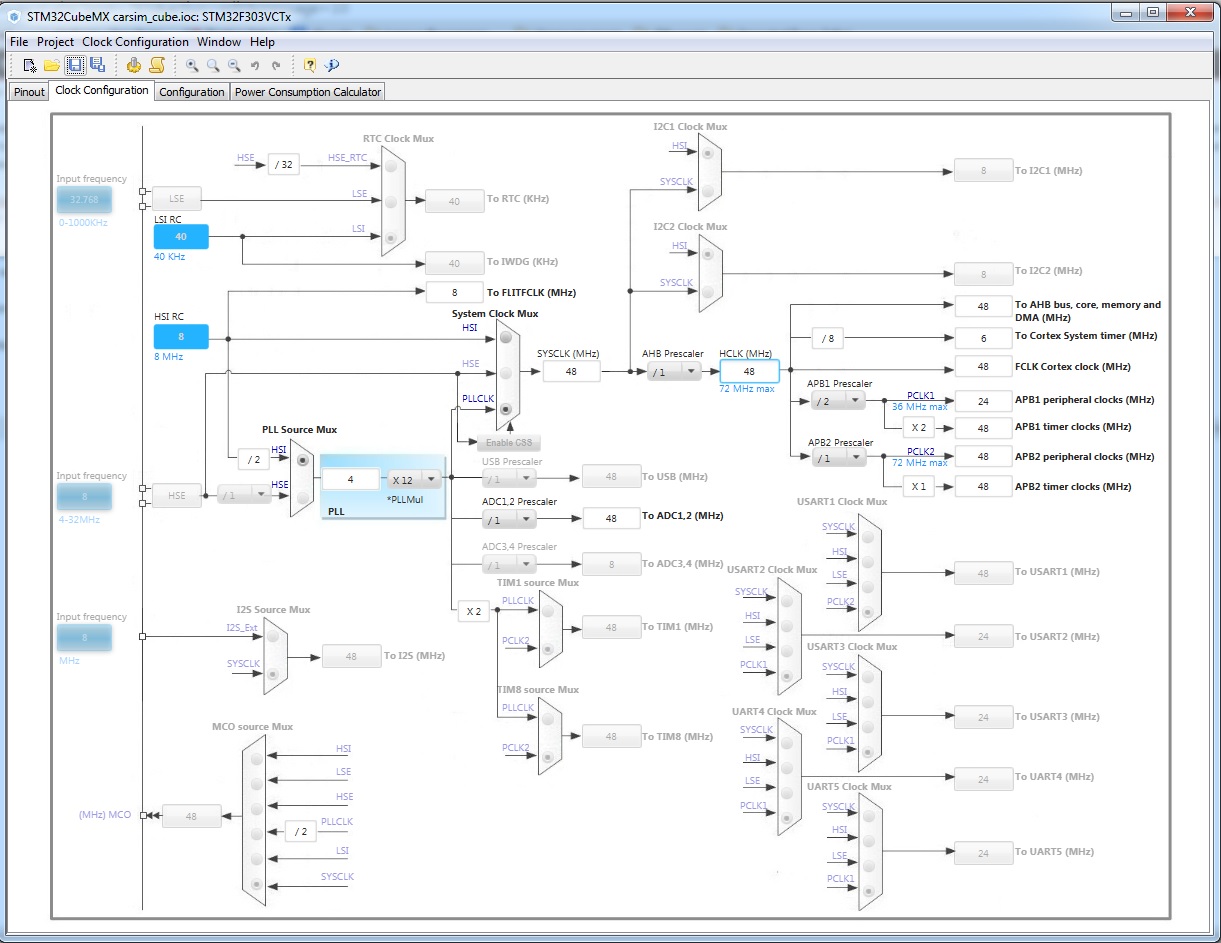
Теперь щелкаем следующую вкладку – Clock Configuration. И у некоторых сейчас порвет мониторы 🙂
На этой вкладке вы можете увидеть, с какой скоростью работают внутренности микроконтроллера. Эта вкладка очень полезна тогда, когда мы озабочены энергопотреблением микроконтроллера. Играясь тут, можно легко на порядок понизить энергопотребление микроконтроллера. Но нам это не надо, поэтому переходим на следующую – Configuration
Тут отображаются те системы, которые будут использоваться в нашем контроллере. Не бойтесь лишних. Просто программа умная и сама добавлят то, что необходимо для жизни микроконтроллера.
На картинке мы видим включенный контроллер ADC1 (для него нужны контроллер DMA, NVIC и RCC) и контроллер GPIO (Для него нужен RCC). В общем, давайте поверим, что нам это надо.
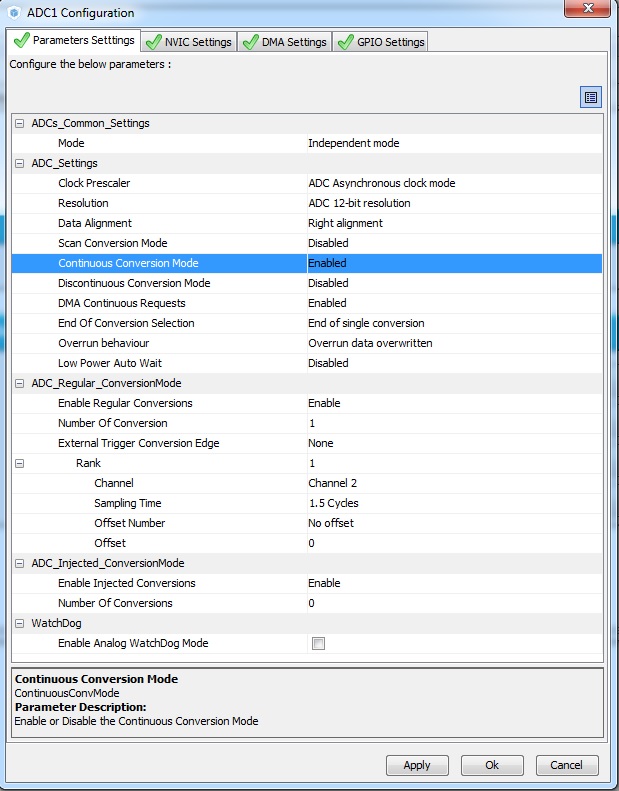
На этом экране у нас есть возможность тонкой настройки. Жмем на ADC1
Тут собраны все тонкие настройки для данного контроллера. Особо менять нечего, за исключением подсвеченного – Continuous Conversion Mode. Поставьте его в Enabled. Данная галочка говорит, что мы желаем запрограммировать контроллер так, что бы он постоянно мерял свои входы. И более того, измерянные значения сразу присваивал переменным. Ну ленивый я, пусть железка сама все делает 🙂
Аналогичную картинку можно получить и по GPIO портам.
Тут можно тоже поизменять разные параметры, но нам тут менять тоже ничего не надо.
В общем, полезная вкладка, особенно когда начинаешь использовать более сложные вещи, как USART или USB – здесь можно настроить все.
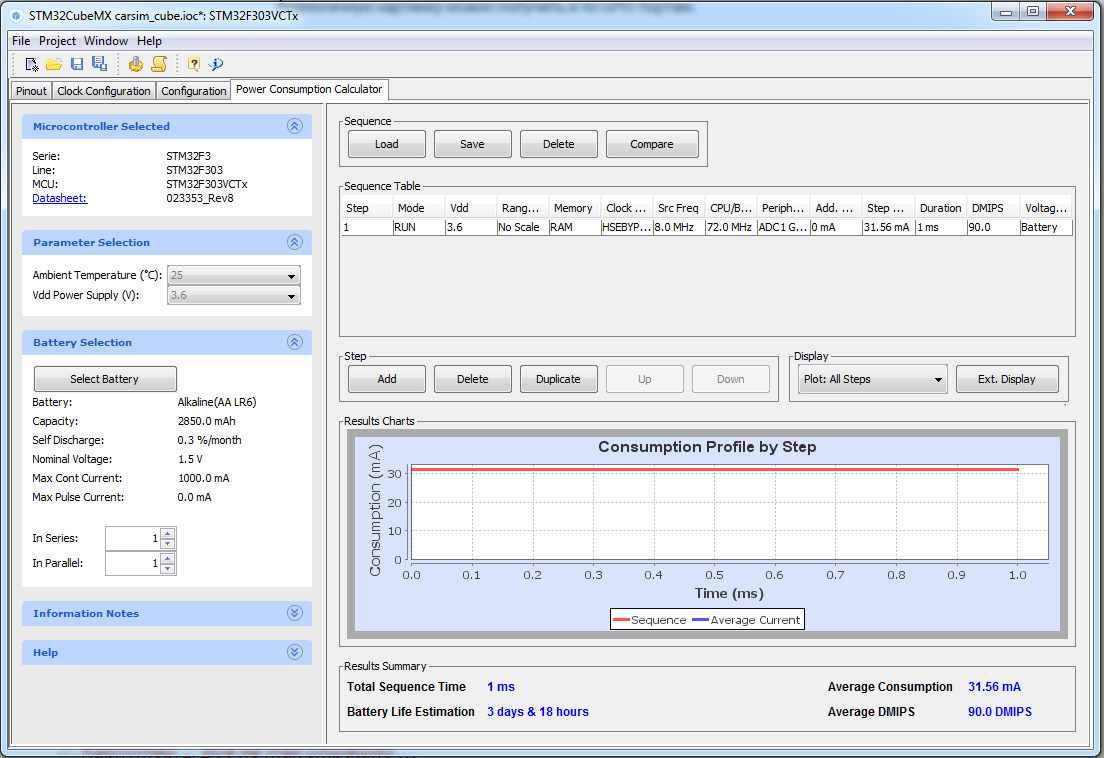
И наконец, последняя вкладка – Power Consumption Calculator. Тут можно прикинуть, сколько электричества будет потреблять микроконтроллер.
Но подчеркиваю, именно прикинуть. Ибо система не знает, сколько потребляет то, что еще подключено к этому контроллеру. На приведенном выше скриншоте я уже понажимал все кнопки. Согласно картинке, если мы ничего не будем подключать к этому микроконтроллеру, то на полной мощности он будет потреблять 30 миллиампер. Или говоря другими словами, от одной батарейки АА он проработает 3 с лишним суток. И это я не тыкал в различные режимы энергосбережения …
Итак, остался один последний шаг. Сгенерировать исходный код, котрый будет компилироваться и прошиваться в контроллер. На панели сверху есть кнопка “шестеренка с палкой”. Нажимаем ее и …
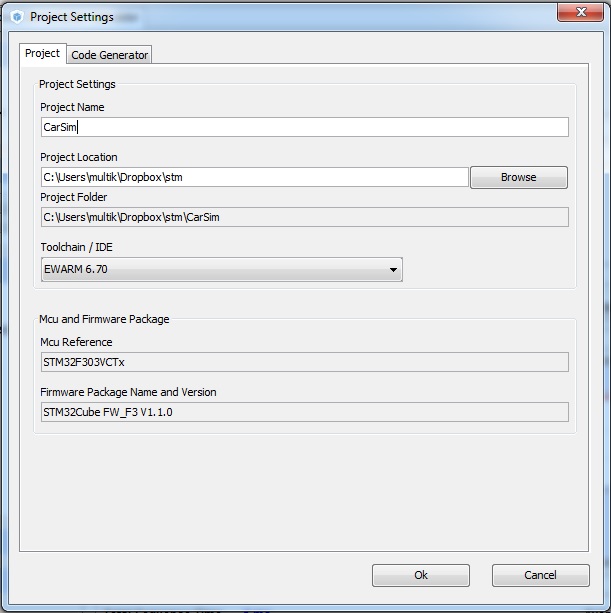
Заполняем, где будут располагаться файлики и как мы обзовем проект. Так же выберем, для какой среды разработки будет генерироваться исходный текст. Выбор небольшой и все предлагаемые системы – полный шлак (тут конечно у каждого свои фломастеры, но тот же бесплатный CoCox уделывает Keil как бог черепаху), поэтому выберите MDK-ARM, как наиболее описанную в русском интернете.
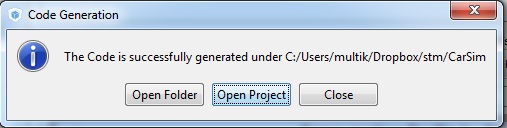
Если вы запускаете генерацию в первый раз, система предложит скачать Firmware Package именно для вашего процессора. Ждем пока скачает и нагенерирует.
Увидели это окошко? Поздравляю! Вы прошли большую часть пути. Остался еще один шаг. Всего один …
Открываем браузер на https://www.keil.com/download/product/ и выбираем MDK-ARM v5. Вам дадут анкету, в которой реально проверяется только email. Проверяется – в смысле их сервер подключается к вашему серверу и проверяет валидность ящика, поэтому емайлы типа 2@1.co не проходят. Остальное нужно только для того, что бы выбрать, на каком языке потом вам напишет продавец со словами “купите у нас”. Как обычно, у данной версии есть ограничения и самым главным из которых является ограничение в объеме кода в 32 килобайта. Поверьте, это довольно приличный объем для микроконтроллеров и вам его хватит надолго. Но если вас это напрягает, то сами знаете где можно найти вылеченную версию совершенно бесплатно.
На данном этапе можете спокойно идти пить чай. Версия, которую вам предлагают, занимает 500 мегабайт и скачаться мгновенно не может. А самизнаетекакая версия занимает еще больше, потому что в нее напихали всякого нужного и ненужного.
Как обычно, рассказывать как ставить программы с помощью нажатия кнопки next, я не буду. Единственное, что при первом запуске вылезет Packs Installer – дождитесь, пока он отработает и закрывайте его. Так что ставьте Keil и в той папочке, куда сохранили проект, найдите каталог Projects, в нем MDK-ARM и там ваш файл с типом mVision4 Project. Нажимаем на него …
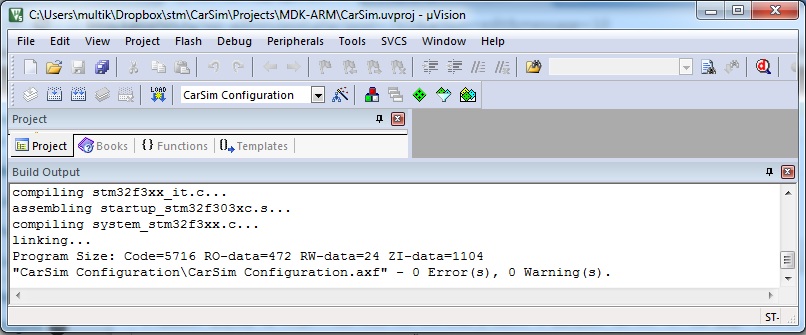
Я тут его немного сплющил, но вы увидите именно это. Теперь нажимаем на кнопочку, которая во втором ряду, под “открыть”. Похожа на папку для бумаг, в которую входит стрелочка. Ну или на клавиатуре F7. Этим мы запускаем компиляцию всего того, чего мы нагородили выше.
И только после того, как вы увидели в окошке снизу строчку 0 Errors(s), 0 Warning(s) вы можете поздравить себя – у вас есть полностью готовая прошивка для микроконтроллера. Ну и что, что она пока ничего не делает, зато 90% нашей первоначальной задачи уже выполнено. Теперь вы можете идти в магазин и покупать реальный микроконтроллер за реальные деньги. И у вас есть уверенность, что он заработает.
А вот как и что подключать к контроллеру – это уже в следующем посте.