Это копия моей статьи, опубликованной на хабре

Почему-то в интернете мало документации про qbs, пора немного исправить эту ситуацию.
Как-то у меня сложилось так, что практически исчезли проекты, в которых надо сделать что-то одно. Обычно надо и написать прошивку для микроконтроллера и управляющую программу для смартфона или десктопа. Можно делать все по старинке: писать код для каждого устройства в родной для него среде разработки.
Но поверьте, это довольно быстро задалбывает. Под виндовс – MSVC, под ARM – CooCox или Keil (приношу свои соболезнования вынужденным работать под IAR), под MSP – CCS, под андроид – eclipse, под ios – Xcode, под пики – MPLAB. И ладно бы, со всем этим работать можно было бы, но ведь фиг: везде свои заморочки, тонкости и неписанные правила. Все это накладывается на общую тормознутость так популярного эклипса помноженную на криворукие дополнения от производителей.
Некоторое время назад я начал сводить все свои разработки под мобильные и десктопные приложения под одну платформу. После довольно долгого чеса по интернетикам мой выбор остановился на Qt. Есть все, что надо, при необходимости можно подцепить нативный код. В общем, задача закрылась.
Но вот с микроконтроллерами ситуация не желала складываться категорически. В основном из-за того, что везде свои хотелки и желалки. Ну ладно, про это я уже жаловался. Я бы еще долго мучался, пока внезапно не наткнулся на краткое описание qbs.
Желающие могут пошариться по инету сами, но если кратко, то это заменитель всяких make и cmake, использующая нормальный (тут должен быть смаил) язык программирования. И сам QtCreator собирается с ее помощью, значит она уже вылезла из штанишек …
Да, документации по ней как обычно кот наплакал, но исходники еще никто не отменял, поэтому довольно быстро ко мне пришло понимание, что это практически то, что я искал. Посудите сами: сидишь в одной среде разработки (самой по себе очень приятной и быстрой) и спокойно пишешь и редактируешь файлы под несколько платформ. И тебе, как кодописателю, пофиг на наличие всяких там заморочек с “родными” средами.
Хватит излияний, пора попробовать. Создадим очень простой проект, в котором у нас будет десктопная и микроконтроллерная составляющая.
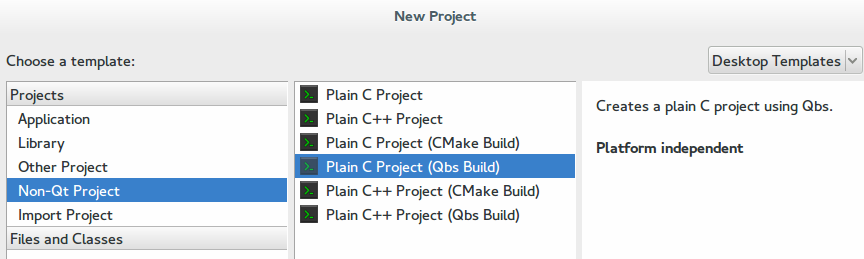
Открываем QtCreator, выбираем создать Non-Qt Project (что бы пока не заморачиваться сильно) и далее выбираем то, где присутствует C и Qbs. Обратите внимание на приятные взгляду слова Platform independent
В результате получаем один main.c и qbs. Можно уже нажать “build” и получить вывод Hello World.
Открываем qbs и ничего не понимаем. Поэтому все стираем, вооружаемся интернетом и начинаем писать. Яваскрипт и все такое.
import qbs
Так, тут вроде понятно. Импортируем всякое необходимое для работы самого qbs.
Project {
name: "simple"
}
Сохраняем и наблюдаем исчезновение main.c с левой панели. При попытке запустить проект QtCreator спросит: а чего пускать-то? В принципе пока все логично.
Из чего состоит проект в терминологии qbs? Из продуктов. И их может быть несколько, но пока я сделаю один.
Project {
name: "simple"
Product {
name: "desktop"
}
}
Теперь для нашего “десктопного” укажем исходник.
Project {
name: "simple"
Product {
name: "desktop"
files: "main.c"
}
}
При попытке скомпилировать не изменится ровным счетом ничего. Подсмотрим в некоторые обучалки и добавим зависимость от cpp и укажем, что вообще-то это приложение.
Project {
name: "simple"
Product {
name: "desktop"
files: "main.c"
Depends {name: "cpp"}
type: "application"
}
}
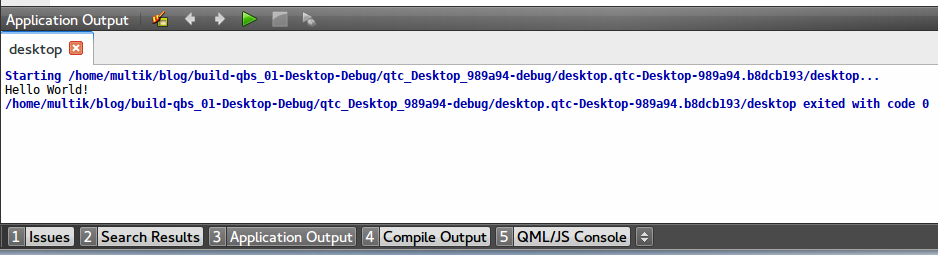
И вот теперь при попытке собрать приложение QtCreator пошуршит немного диском и в панельке Application Output появится искомое
Ага, значит мы на верном пути. Осталось разобраться, что делают те самые две магические строки.
Depends {name: "cpp"}
Читаю документацию и понимаю, что данной командой я устанавливаю зависимость проекта от какого-то модуля с именем cpp. Понятней стало? Мне нет.
Простым поиском нахожу что-то подобное в /usr/share/qtcreator/qbs/share/qbs/modules/ (Если у вас другая операционка, то скорее всего аналогичное лежит где-то неподалеку от QtCreator). Если говорить коротко, то там куча яваскрипта, которая в зависимости от платформы подбирает компилятор под эту платформу. Полностью повторять подобное мне смысла нет, поэтому оставляю как есть.
type: "application". Из документации: The file tags matching the product’s target artifacts. Артефакт … An Artifact represents a single file produced by a Rule or Transformer. … ерр .. Rule? Creates transformers for input tags. Напоминает ситуацию про сепулькарий .. Transformer? Creates files, typically from other files.
Ползаю по доступному и понимаю, что примерно это некий набор правил, который говорит системе сборки, как надо собирать скомпилированное. Ну грубо говоря, на выходе надо получить приложение, библиотечку или вообще что-то иное. Опять же, хоть и стало немного понятней, но ненамного. Опять пока примем за данность.
Но вернемся к нашему проекту. Давайте добавим еще один продукт, только уже для микроконтроллера
Project {
name: "simple"
Product {
name: "desktop"
files: "main.c"
Depends {name: "cpp"}
type: "application"
}
Product {
name: "micro"
files: "blink.c"
}
}
При попытке что-то сделать, нам сразу выскочит сообщение, что вообще-то файла blink.c нет. Ну, ок, добавим в проект фаил blink.c. Как видно из названия, это тот же HelloWorld, только для микроконтроллеров. Я взял из примеров для микроконтроллера семейства msp430.
#include <msp430.h>
int main(void)
{
WDTCTL = WDTPW + WDTHOLD;
P1DIR |= 0x01;
while (1) {
P1OUT ^= 0x01;
__delay_cycles(1000000); // 1 second @ 1MHz
}
return 0;
}
Будучи скомпилированным и залитым, он начнет дергать ножкой P1.0 с интервалом в одну секунду. А так как на этой ножке у большинства демо- и девелоперских плат висит светодиодик, то он замигает.
Теперь QtCreator не ругается, но и в микроконтроллер ничего не заливается. Странно, да?
Добавлять Depends {name: “cpp”} смысла нет, потому что установленный в системе родной gcc не в курсе про существование такой платформы, да и в дальнейшем пригодится, например для пиковских контроллеров, где вообще все свое.
Теперь воспользуемся обрывками тех сакральных буковок, что встретились раньше.
Для начала, я предпочитаю в микроконтроллерных проектах расписывать каждый функционал в своем файле. Записывать каждый файл руками? Лень. Подсматриваем решение и переписываем блок
Product {
name: "micro"
Group {
name: "msp430 sources"
files: 'src/*.c'
fileTags: ['c']
}
}
Тут создаем группу файлов, которые обзываем “msp430 sources” и тупо включаем в нее все файлы, которые подходят под маску src/*.c. Для дальнейшей работы с ними тегируем их буквой С.
Что с ними делать? У qbs есть на этот случай две штуки – Rule и Transformer. По сути они близки, но немного разные. Счас попробую описать на пальцах разницу.
Rule умеет срабатывать на каждый файл, попадающий под что-то. Может срабатывать по разу на каждый фаил (например, для вызова компилятора), а может один раз на все (линкер).
Transformer предназначен для срабатывания только на один фаил, с заранее определенным именем. Например, прошивальщик или какой-нибудь хитрый скрипт.
Ок, добавляем правило, которое должно будет сработать на все наши файлы, промаркированные как “с”.
Product {
name: "micro"
Group {
name: "msp430 sources"
files: 'src/*.c'
fileTags: ['c']
}
Rule {
inputs: ["c"]
prepare: {
var cmd = new JavaScriptCommand();
cmd.description = "file passing"
cmd.silent = false;
cmd.highlight = "compiler";
cmd.sourceCode = function() {
print("Nothing to do");
};
return cmd;
}
}
}
В принципе из синтаксиса уже все понятно. Есть inputs, есть prepare, в который засовывается яваскрипт, который выполняет необходимое. В данном случае он должен в окошке Compile Output показать file passing, и куда-то вывести Nothing to do. Ну по документации вроде так.
Запускаем перекомпиляцию всего и смотрим. Не знаю, как у вас, но я ничего не вижу. Почему? Потому что qbs больно умный, а документация к нему страдает лакунами.
Правило не срабатывает, потому что qbs считает, что оно не производит никаких действий в системе и от него ничего не зависит. В принципе это соответвует реальности, но провести проверку мешает.
Ок, за это отвечают те самые артефакты. Под ними подразумеваются результаты деятельности Rule или Transformer. Лучше всего это объяснить на примере компиляции. Когда мы компилируем .с файл, то на выходе мы получим объектный файл .о. Он нам нужен для дальнейшей линковки, но с другой стороны, мы его можем удалить, так как потом спокойно сможем сгенерировать заново.
Опять копируем пример из документации и чуть-чуть модернизируем.
Rule {
inputs: ["c"]
Artifact {
fileTags: ['obj']
filePath: '.obj/' + qbs.getHash(input.baseDir) + '/' + input.fileName + '.o'
}
prepare: {
var cmd = new JavaScriptCommand();
cmd.description = "Compiling "+ input.fileName
cmd.silent = false;
cmd.highlight = "compiler";
cmd.sourceCode = function() {
print("Nothing to do");
};
return cmd;
}
}
Теперь мы говорим, что после нашей деятельности останутся артефакты в каталоге .obj (ну и я добавил вывод того, над каким файлом мы сейчас работаем). Запускаем. Опять ничего в ответ. Почему? Ответ тот же – никому не нужны файлы с тегом ‘obj’.
Хорошо, для проверки сделаем так, что они нужны нам. И вообще, наше приложение – это один сплошной obj.
Product {
name: "micro"
type: "obj"
Group {
name: "msp430 sources"
files: 'src/*.c'
fileTags: ['c']
}
Rule {
inputs: ["c"]
Artifact {
fileTags: ['obj']
filePath: '.obj/' + qbs.getHash(input.baseDir) + '/' + input.fileName + '.o'
}
prepare: {
var cmd = new JavaScriptCommand();
cmd.description = "Compiling "+ input.fileName
cmd.silent = false;
cmd.highlight = "compiler";
cmd.sourceCode = function() {
print("Nothing to do");
};
return cmd;
}
}
}
Пробуем, и удача! В окошке появился заветный “Compiling blink.c”. Теперь давайте добавим, что бы оно реально компилировало и сразу по-быдлокодерски, то есть тупо забив все необходимое в одну кучу.
prepare: {
var args = [];
args.push("-mmcu=cc430f5137")
args.push("-g")
args.push("-Os")
args.push("-Wall")
args.push("-Wunused")
args.push('-c');
args.push(input.filePath);
args.push('-o');
args.push(output.filePath);
var compilerPath = "/usr/bin/msp430-elf-gcc"
var cmd = new Command(compilerPath, args);
cmd.description = 'compiling ' + input.fileName;
cmd.highlight = 'compiler';
return cmd;
}
Перекомпилируем все с нуля и смотрим в каталог .obj
$ ls -R1
.:
f27fede2220bcd32
./f27fede2220bcd32:
blink.c.o
Ура! Файлик появился. Теперь, для проверки я делаю еще один файлик, с хитрым названием hz.с. Если я прав, то после перекомпиляции рядом появится еще один объектный файл.
В выводе появилось
compiling blink.c
compiling hz.c
а в каталоге
./f27fede2220bcd32:
blink.c.o
hz.c.o
Все вроде ок. Теперь необходимо все это дело слинковать. А значит опять правило, только теперь для линковки.
Rule {
multiplex: true
inputs: ['obj']
Artifact {
fileTags: ['elf']
filePath: project.name + '.elf'
}
prepare: {
var args = [];
args.push("-mmcu=cc430f5137")
for (i in inputs["obj"])
args.push(inputs["obj"][i].filePath);
args.push('-o');
args.push(output.filePath);
var compilerPath = "/usr/bin/msp430-elf-gcc"
var cmd = new Command(compilerPath, args);
cmd.description = 'linking ' + project.name;
cmd.highlight = 'linker';
return cmd;
}
}
Где отличия? Во-первых, добавился флаг multiplex, который говорит о том, что это правило обрабатывает сразу все файлы данного типа скопом. А во-вторых, во входных параметрах исчез input. Появился inputs, который является массивом файлов данного типа. Ну и я вопользовался именем продукта, что бы брать имя для финальной прошивки.
Ставим тип приложения elf и пробуем собрать. Через некотрое время мы в каталоге для сборки обнаружим файл simple.elf
$ file simple.elf
simple.elf: ELF 32-bit LSB executable, TI msp430, version 1, statically linked, not stripped
То, что нам и необходимо. Его можно уже заливать в плату и наслаждаться мигающим светодиодиком.
Исходная цель достигнута: мы в одной среде разработки делаем все: и редактирование и компиляцию.
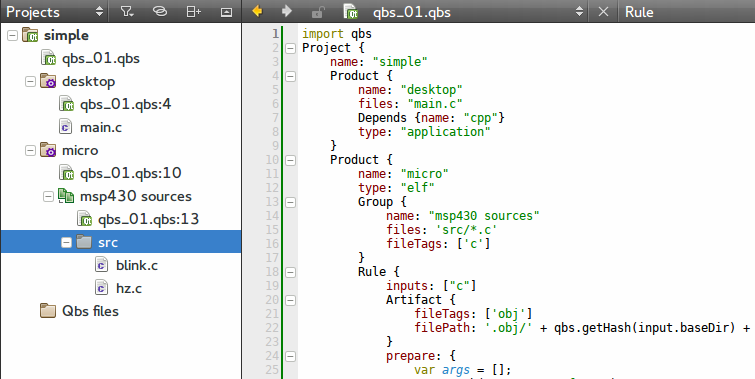
На всякий случай конечный qbs
import qbs
Project {
name: "simple"
Product {
name: "desktop"
files: "main.c"
Depends {name: "cpp"}
type: "application"
}
Product {
name: "micro"
type: "elf"
Group {
name: "msp430 sources"
files: 'src/*.c'
fileTags: ['c']
}
Rule {
inputs: ["c"]
Artifact {
fileTags: ['obj']
filePath: '.obj/' + qbs.getHash(input.baseDir) + '/' + input.fileName + '.o'
}
prepare: {
var args = [];
args.push("-mmcu=cc430f5137")
args.push("-g")
args.push("-Os")
args.push("-Wall")
args.push("-Wunused")
args.push('-c');
args.push(input.filePath);
args.push('-o');
args.push(output.filePath);
var compilerPath = "/usr/bin/msp430-elf-gcc"
var cmd = new Command(compilerPath, args);
cmd.description = 'compiling ' + input.fileName;
cmd.highlight = 'compiler';
return cmd;
}
}
Rule {
multiplex: true
inputs: ['obj']
Artifact {
fileTags: ['elf']
filePath: project.name + '.elf'
}
prepare: {
var args = [];
args.push("-mmcu=cc430f5137")
for (i in inputs["obj"])
args.push(inputs["obj"][i].filePath);
args.push('-o');
args.push(output.filePath);
var compilerPath = "/usr/bin/msp430-elf-gcc"
var cmd = new Command(compilerPath, args);
cmd.description = 'linking ' + project.name;
cmd.highlight = 'linker';
return cmd;
}
}
}
}
PS Вынос “захардкоденных” переменных в более удобное место оставлю на вашей совести, ибо это уже к обучалке по яваскрипту.